GAMES第一期学术沙龙观点集锦
GAMES第一期学术沙龙观点集锦
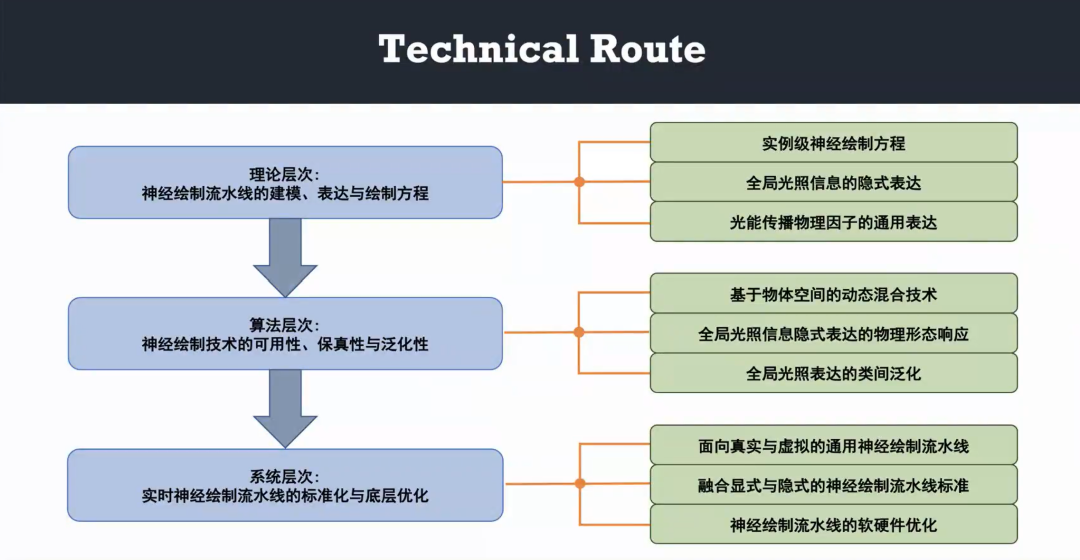
三维图形的神经隐式表达及其问题与挑战
活动背景介绍
GAMES学科沙龙是CCF CAD&CG专委会GAMES新开展的关于学科发展的学术研讨活动。沙龙拟采用邀请制的方式,与会者围绕某个具体的学科问题进行较为深入的研讨,秉持真理越辩越明的原则,敢于对主题内容持有与发表自己的观点和意见,开展真正意义上的学术思辩,既有“思”(深入思考,有自己鲜明独特的观点),又有“辩”( 激烈辩论,可以有不同观点),提倡百家争鸣的学术氛围。
沙龙结束后,组织方将整理完整的研讨会文稿,如实记录研讨会思辨过程,并公开发表在GAMES平台,以启发更多同行的思考,推动学术交流和学科发展。
沙龙研讨主题:三维图形的神经隐式表达及其问题与挑战
组织者:刘利刚、童欣、张举勇
时间:2022年9月24-25日
线下发言嘉宾:鲍虎军、刘利刚、许岚、许威威、张举勇、周晓巍
线上发言嘉宾:高林、过洁、韩晓光、刘烨斌
文字整理:蔡泓锐、彭博
主讲嘉宾发言实录
开场白:


张举勇(中国科学技术大学):首先介绍下这次学术沙龙的背景,这是GAMES学科沙龙的第一次尝试,主题为:三维图形的神经隐式表达,问题与挑战。再介绍下研讨会的目的,其实现在国内的学术会议挺多的,但是我个人感觉学术会议中关于学术的讨论还是不太够。另外的话我也觉得之前大连CAD&CG会议中关于NeRF的讨论形式挺好,但是由于时长只有一个小时到一个半小时,讨论的还不是很充分。最后一点是参会人数也比较多,有时可能讲得不够开,离真正的思辨还有距离。因此,我们探索采取邀请制形式(比如不超过10人),围绕某一个具体topic进行深入讨论,讨论时如实地把讨论内容记录下来,最终形成文稿分享出来,以达到启发我们学科更多人思考的目的。
然后解释下为什么选择神经隐式表示这个主题,应该是从2018年开始,当然之前也有更早的相关研究工作,神经隐式表示在三维视觉和计算机图形学的不同任务中展现了巨大潜力。包括早期的 Occupancy Net和IDR等工作。而2020年的NeRF彻底地引爆了相关研究。所以可以说神经隐式表示或神经渲染方法应该还是当前图形学和三维视觉最火的topic。同时国外的一些相关研究机构以及国内的CCF CV专委会,他们其实都组织了相关的研讨,而我们国内图形学领域虽然在一些会议上有这样的研讨,但还是缺少非常有针对性与系统性的研讨,所以很有必要去组织这么一个活动。这个活动采取线上线下结合的方式,我们每位老师先分享自己的相关工作与观点,再针对之前收集到的问题逐一展开讨论。在讨论中我们希望有些观点是针锋相对的。非常感谢各位老师在繁忙的工作中抽出时间参会。
鲍虎军(浙江大学):人工智能和图形学的融合是一个趋势。对图形学来说,结合这个趋势我们要思考如何借鉴人工智能的思想和方法去指导图形学的变革,这是一个非常重要的事情。其中NeRF是一套非常好的思想方法,现在也发展得很快,而且这个方法未来可能还会解决更多问题。所以在这种背景下,大家可以从不同的观点以不同的视角进行讨论。在群里大家收集了很多相关问题,这些问题无非涵盖两个视角,即三维视觉的角度和图形学的角度。最近AI for Science实际上是探索用人工智能的思想方法去解决科学计算里面的一些问题。而以几何和物理的视角来看,图形学本身可以看成是一种科学计算。所以在这种情况之下,不管落脚在建模还是绘制等图形方向,我们都需要去考量用这样的一套思想和观点来研究重构图形技术,未来甚至可能变革硬件架构。例如现在的GPU很强大,但它在一些地方的发展还是有局限性的。所以我们希望真正地思考并讨论下对我们这个领域有指导意义的一些思想和方法,抛出的观点不见得都是正确的,但是这样的讨论对图形学学科的发展将起着很好的推动作用。
刘利刚(中国科学技术大学):这种学术沙龙的研讨形式一直是我们想尝试和探索的,即我们讨论时提出的观点可以不一定完全正确,但可以多思辩、要百家争鸣。这次我们针对神经隐式场这样一个研究方向,来讨论它的潜力以及是否还有继续挖掘的东西,能否形成一些引导性的思路和方向?线上线下的各位老师可以随时发表意见和想法。希望这两天通过思辨和研讨真正能产生一些具有深刻价值的洞察。比如我先抛出一个问题,3D物体的隐式表达早在几十年前就有了,但为什么近几年突然火爆?是因为神经网络的表达能力强还是有其它因素?如果这种形式的研讨沙龙效果好,之后我们会大力推广。
张举勇(中国科学技术大学):那我们先请各位老师分享下相关的研究工作与看法,就按照姓氏顺序依次分享。
鲍虎军老师分享
鲍虎军(浙江大学):我想在座的老师更多地从视觉角度来探讨光场的神经隐式表示和重建问题,而我现在主要是从图形绘制的角度来讨论它,我估计等一下刘利刚老师会从几何的角度去讲。我觉得NeRF在图形绘制领域的探索会是未来一个非常重要的方向。主要需要思考怎么样用NeRF的一些思想来做光场的属性参数表达和传递,这个表示和传递将引发图形绘制方程和绘制模式的重构,包括绘制流水线的重组。所以我想从绘制的角度去谈NeRF思想的正向模拟应用,即思考怎么用其来解决绘制问题,这是我认为潜力非常大的一个方向。从理论上讲,虚拟现实、图形学以及三维视觉等方向都在考虑数字空间与物理空间的交融。从视觉的角度来看这个交融实际上体现在两个方面,即显示与感知。三维视觉探索如何来构建数字空间,而数字空间最终的呈现要返回到物理空间,即返回到用户的面前,也就是三维图形追求的目标。感知与呈现的这条线一直是双向的,三维视觉感知探索了二维影像的神经网络三维表示和学习机制,而呈现所对应的图形技术则从绘制方程、绘制流水线出发研究图形的合成机制,整套东西都是以三维场景为载体。
但是从方法论上,视觉引发了深度神经网络的一套智能化机制,而图形本质上是一套模拟仿真机制,目的是基于物理的描述,即通过物理方程去模拟这样一个机制。实际上这两个方法长期以来一直逐渐融合,2000年以来,像image-based modeling & rendering等很多技术实际上都试图去做融合,包括图形学的纹理建模和映射等,都是去想解决这件事情。这些思路在图形绘制方面的体现包括绘制流水线,例如GPU架构,它的目标是把物体表达为海量的三角形单元,并用这些单元去做光栅化,从而生成图像。但它并不能提供像光线跟踪或者辐射度那样的那种全局光照计算,而是用光栅处理来做局部近似。大家回过头来看图像处理方向,它涉及到的各种算子,现在都是走人工智能这一套,这些算子都是比较轻量的,所以很多情况下用CPU就可以处理。但图形不一样,它每个三角形单元的处理都非常复杂,导致它非常需要密集的并行计算,因为光栅化处理时它的像素数量非常多,所以在这种情况下要求GPU有一个高度并行的机制,这样才能推动传统光栅化技术的变革。现在Nvidia推出的光线跟踪引擎,就是模拟了全局光照的一些效果。这样的GPU内核实际上蕴含了两套体系。这是Nvidia的图灵架构,它有面向AI的Tensor Core,有光线跟踪引擎RT Core,当然还有传统图形光栅化的Shader Core。所以这样的芯片实际上混杂了一些特定的目标,而普适化的处理需求导致了其架构的复杂化。
所以在这种情况之下,实际上现在有这两条硬件加速路线,一条是深度神经网络学习加速计算架构,一条是光栅化与全局光照计算的混合图形流水线。深度学习这边就变成了NPU/TPU那种AI芯片架构,另外一边是光栅化Shader和RT Core的混合。从技术层面上看这两个芯片的处理实际上还是各有千秋的,所以现在芯片的发展实际上要把两个混在一起,其中简单地把NPU跟GPU融在一起就形成现在的图灵架构,但实际上还是分离的。所以我认为未来可能会出现深度学习的图形处理器单元,我这里把它叫NGPU。这样的一个单元既兼容了Deep Learning,又兼容了Neural Rendering的那种绘制框架,也就是绘制流水线。其中对Deep Learning的支持比较容易,但是如何改造传统绘制流水线蕴含着巨大挑战。所以我们的研究初衷就是希望用NeRF的思想来解决绘制方程的全局光照计算问题。在计算求解中如果把NeRF看成是简单地采集一些信息来重建和绘制,某种程度上它是一个可视化的范畴。但是全局光照明绘制不是这样的,它要求场景中的光照、材质、几何、外形以及运动等要素都是可变化的,所以它涉及到光的反射、透射以及阴影等空间相互作用,它的计算要求实际上是很复杂的。我们的一个核心思想就是如何把一个物体实例化,即以物体为绘制单元。我们预先用深度神经网络来参数化表达一个物体局部光场的属性,进而构建一个深度神经网络模型来刻画景物间的光能传递,即将物体逐一嵌入到场景中,并考量场景的光场是如何变化的。如果这个变化能刻画出来,那么在推理阶段就可以很方便地呈现出如光源、物体材质、阴影等属性变化后的绘制效果。

所以基于这样一种思想,我们架构了这么一套分层次的系统,先做一个背景的光照计算,同时把一个在别的场景当中预计算好的物体实例扔进去并呈现其光场的改变。这种策略具有高度的并行性。我们已经验证了刚性物体的泛化能力,包括旋转平移、材质改变、光源变化等。在一般的场景下全局光照计算都能达到实时的帧率(25~40)。现在的反射我们就跟踪了两次,否则的话计算量会更大。我们已取得比RT Core更好的效果和效率,也比现在的AI全局光照计算结果要好。我们称之为实例化的神经绘制方程求解方法,实际上它是以一个刚性物体作为实例单元,抛弃了原先的三角形单元绘制架构,用NeRF思想去表达、逼近绘制方程,其中一方面需要考量到底怎么样来隐式地表达全局光照信息,另一方面如何重构绘制方程,即光在传播当中物理因子(如材质、光源等)怎么样通用地表达。
第二个在算法层面,非常重要的是可用性、保真性以及泛化性。因为实例是在特定场景预先采样而建模的,所以必须要证明放到任意光照条件、环境下它的呈现都是合理的。另外,我们现在的光场是以一个刚性物体作为对象,所以还要探索物体形变的处理。还要考虑一个粒子系统如何处理?半透明的物体如何处理?这些可能会引发一系列的技术变革。最后要考虑一些物理形态的问题,如动力学以及光照、类别之间的泛化等。这都需要更多的研究。有了这些以后,要考虑硬件底层怎么变革,标准化跟底层优化都非常重要,在这里面实际上有两个问题,一个是NeRF方法本质上是对真实场景的刻画,所以引入标准NeRF后绘制流水线如何变化?另一方面,我们可能需要很长一段时间来探索传统三角形网格表示与隐式神经表示的融合,现在物体局部光场是用标准的三角形单元绘制流水线去预采样并训练建立其属性参数表示的。第三件事情就是要思考硬件如何优化,实际上我们已经设计了一个硬件的架构,首先需要有一个比较大的G-buffer,用于空间计算。总结一下,在神经图形绘制流水线的架构会有一个很大的变化,可能整个体系都要逐步重构,我们的初步探索证明这个是可行的。
刘利刚(中国科学技术大学):这种通过光场传输来计算每个像素的颜色,是否只能在这个场景中使用?因为训练场景和应用场景的光照可能不一样。
鲍虎军(浙江大学):我们已经证明了这套系统具有跨场景、刚体运动等泛化性,可以满足大多数场景,因为在光场的采样时其实给定了一个光源,并有一套采样重构的属性参数表达机制。一方面是光,一方面是材质,现在反射用的还是BRDF。
许威威(浙江大学):Light Transport过程中有物体和光源之间的visibility的问题,例如以前做PRT或Real-time GI都要有visibility这一项。Light Transport指的是光源如何达到物体的某个点,shading是指如何计算某个点在光照下的反射。我是这样理解的。
鲍虎军(浙江大学):有两种近似处理方法。一种是以物体为中心观测四周,获得深度图,可以显式剔除被遮挡光源。另外一种是把深度图放到作为网络输入,做隐式剔除。考虑特殊情况下对物体产生影响的光线可能不经物体中心,第二种更完备,但对数据量要求更大,目前版本用第一种。
许威威(浙江大学):对场景进行光栅化绘制可以解决场景在视点下的可见性问题,我的疑惑是物体和光源的可见性问题在这个框架下是如何解决的?光源照不到的地方会产生阴影。
鲍虎军(浙江大学):实际上这个类似于PRT,取物体的中心作为视点,由G-buffer来近似计算其visibility。
高林老师分享
高林(中国科学院计算技术研究所):不同于传统的点云、三角网格表示,我们现在用网络来理解几何是一个非常新颖的表征方式。从几何建模的角度来看,这段时间隐式场表示非常热门,在几何上有一个全新的渲染方式。这些基础知识我就不赘述了。然后主要说下NeRF发展面临的一个挑战。NeRF比起传统的表征来说,像刚才鲍老师讲到的,它没有那种解耦的表征,也就是说它不是那么的灵活和可控。并且基于它的重建就是训练一个网络,然后它的渲染就是进行推理,所以说总体上现在面临的一个挑战就是效率非常低。另外它不像传统的渲染方程,以往都是非常好去显式地计算光照、阴影的,所以说NeRF怎么去做光照也有很多挑战。然后还有这种动态场景对NeRF来说也是非常难处理的,所以说NeRF可能现在可视化的效果很好,但是相比经典的渲染管线来说,它的问题依然是非常多的。NeRF它原始的模型其实是非常简洁的,其实就是对空间的一个位置进行翻译,采样一个点直接得到它的颜色值和密度值。有了NeRF之后重建方向如果按照内容来分的话,其实就是数字人,然后物体以及场景,其中有一些不同。人脸场景中数据集很多,有很多同行积攒了很多各个视角的数据集,这就使得人脸的生成模型很好做。另外人脸的几何比较规整,而且人脸相对容易对齐。有了人脸生成模型之后我们可以做很多应用,例如很多工作能在几个稀疏视角(包括单视角)的设定下做人脸三维重建。有了生成模型后一个直接的好处是可以做编辑,编辑可以作为约束或者作为条件,可以去合成3D的人脸。
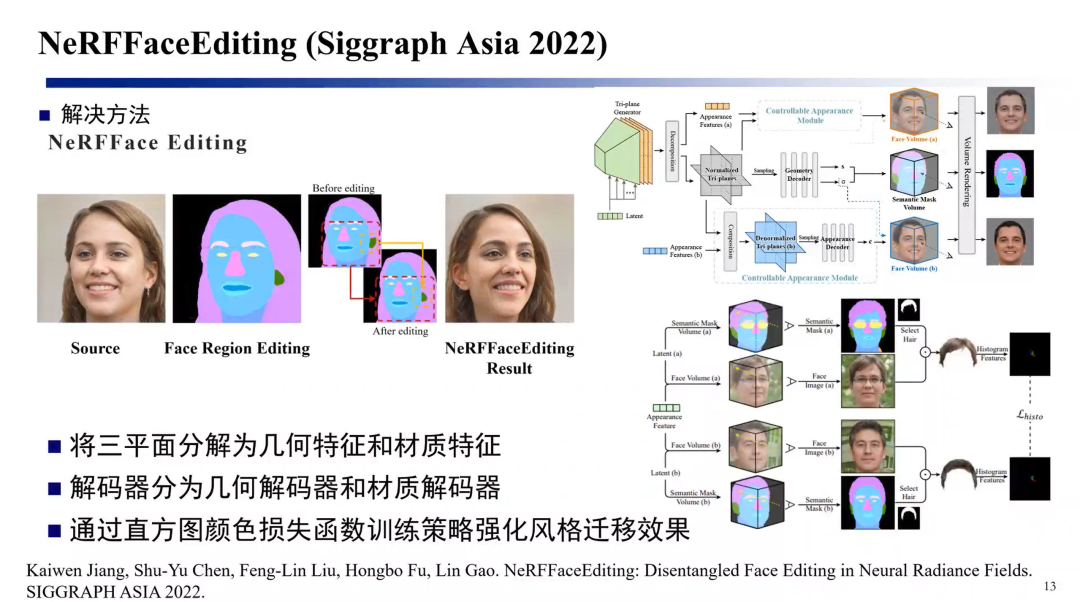
有一个平行的工作,是清华刘烨斌老师和腾讯AI Lab合作的工作,在做NeRF的人脸编辑。然后我介绍一下我们这个方案,就是我们这个方案本身上它还是一个生成模型,它借助了三平面生成模型的一个优势,就是把这个模型这种立体的生成转到三个平面上,这样处理起来会更容易生成。方案中人脸可以分为几何和材质,可以对立体mask去编辑、去加上材质以进行人脸的合成,这样的好处不光是对3维人脸进行编辑,还可以编辑2维的人脸,例如想把鼻子变得高挺一些,传统PS软件很难做到,但是有了这个以后可以把它映射到三维空间上去理解,然后改变三维立体去做这个人脸的生成。这个工作相当是我们在人脸方面的一个尝试。
另一方面的问题是NeRF训练相对来说比较难,现在一方面instant-ngp提出了一个加速处理的方案,另一方面我们在想能怎么样去利用、获取到先验。一种先验来源于数据集,我们的想法是在传感器上适当地补一些先验。因为现在的iPhone手机是有深度传感器的,有了深度先验以后收敛就会快。
然后还有一个工作,我们也是做了一个NeRF的编辑工作,工作的目的是说要把先验用好,然后用比较少的彩色相机加上深度相机,能比较快地把NeRF重建出来。我们相当于是把深度作为数据先验,这样就可以快速地把NeRF给训练出来。编辑其实我们还是把它转到了显式的解决方案上,网络编辑是很难的,我们只能说是编辑光线,编辑光线的话就需要有一个外部的代理,我们先通过NeuS把表面的网格给它重建出来,重建了表面的网格以后就有了体网格,这时它的变形就转化成对空间的扭曲。这样的扭曲实际上是扭曲了光线。这里有个对偶的效果,扭曲光线等于扭曲物体,从而可以对这个模型生成一个变形的效果。鲍老师、章老师和崔老师在ECCV 2022也有一个几何和纹理编辑的工作。
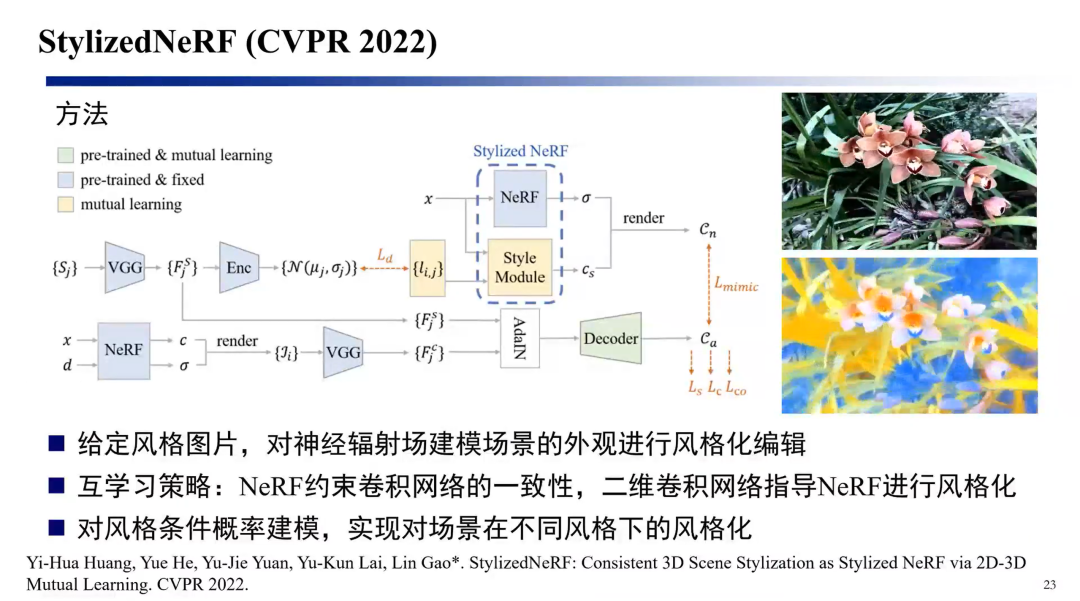
然后另一个问题是改变NeRF的纹理,这里有一个大家都经常做的问题——Style Transfer。输入是视频序列,在视频序列上进行训练,得到3D表示。其实直接的方案就是说能不能把视频序列直接风格化后转过来,但这里会带来一个问题,就是把结构给破坏了。我们现在训练了两个网络,一个网络负责风格化,另一个网络是用NeRF在做监督,我们要在训练的过程中保证3D结构同时改变它的纹理特征,这是一个纹理风格化的工作。
然后接下来可能就是想因为数字人要做得真实,还是要有些动态细节。人脸相对来说它的先验会比较多,而人体先验是很少的,并且动态细节是非常多的。所以如何用比较少的这种视角去刻画这种精细的、这种完整的3D数字人可能是目前最想解决的一个问题。另外一个问题就是说编辑虽然我们已经做了一些工作,但总体来说它离PS这种非常好用的软件距离还是比较远。本身NeRF可能现在也没有这么普及,还要思考如何在NeRF上做重光照、加阴影。现在我们遇到的这个困难,就是如何跟传统的管线很自然地结合起来。还有一个就是说在空间尺度上对整个城市的模拟。设计的这个网络不止去拟合它的颜色、空间位置,还可以拟合它的物理属性,其实这方面可能也是有很多可以挖掘探索的地方。接下来可能就是时空维度上都还有很多要挑战的地方,包括时间维度上的高动态,例如在视角约束比较少的情况下的高动态场景。另外用无人机航拍去重建整个城市,如何在应用层面上、在终端上(如手机、VR头盔)上浏览,未来是不是会在VR上看到基于NeRF的芯片?可能还有一些其它的方面,比如说在医学影像方面可能也存在一些应用的价值。
刘利刚(中国科学技术大学):对于从多张图片来重构三维表达,不管是以前的MVS重建还是现在的NeRF重建,都是需要精确的相机位姿的正确估计。如果这个相机位置估计不好,怎么都做不好,对吧?现在大部分NeRF的工作也是假定相机位姿是给定的。也有些工作同时去优化相机位姿,比如NICE-SLAM,这些工作是否对相机位姿估计是否有促进作用?
鲍虎军(浙江大学):那肯定,不光pose,后面的高精度注册也是一个很大的问题。
许威威(浙江大学):其实NeRF对相机位置的处理是可以的,不光是NICE-SLAM还有Volumetric BA也是这么做的,从结果看它的精度会比原来基于feature特征点的方法稍微好一点。
鲍虎军(浙江大学):这个是改变了,因为原来的MVS是一步步过来,每一步无法回溯,有问题的地方它回归不回去。现在NeRF这一套若初值不好,我可以调整它的特征,看下匹配哪一步做得不好。这个是NeRF最大的一个优势。
许岚(上海科技大学):感觉还是优化方法本身的问题,原来处理用的还是gradient descent,现在NeRF还是好一点。
许威威(浙江大学):我觉得隐式表示最大的一个好处可以处理diffuse以外的场景。最近的工作能把diffuse和specular的地方在场景中划分出来。硬生生地分为两部分做高光、做去除。
张举勇(中国科学技术大学):我认为还是要把structure和detail分开,先用特征点搞出structure,得到初始信息,再在这个基础上做refine。
许威威(浙江大学):MLP这里有个global的约束,是个全局的function。
过洁老师分享

过洁(南京大学):这是我们在NeRF上做的第一篇工作,刚刚被Siggraph Asia给接收。我们最近在思考如何借助NeRF来做传统的渲染,但是目前来看NeRF的局限性比较多。一个局限体现在我们现在做的传统渲染任务,对画质、分辨率的要求非常高。现在传统渲染任务的画面分辨率至少要做到1080p,也就是1920×1080这样高的一个分辨率。在这样一个分辨率下,NeRF基本上跑不出来太多的细节,结果的话基本上都是糊成一片。我看现在好多NeRF的工作处理的分辨率大概都是几百乘以几百这样的分辨率,其实从传统渲染的需求来看远远不够,这个可能也是后续我想和大家探讨的一个问题。包括前面两位老师也提到Relighting这件事情,我们也意识到这是件有挑战的事情。

这里我们的输入的是unconstrained scene,并蕴含不同的光照条件、不同视角等变化的因素。我们希望在这样一个输入的前提下能用NeRF的方法重建出场景的隐式表示,能够同时支持传统的view synthesis和relighting,尤其是对于这种室外的场景。我们这里借鉴了NeRF in the Wild的一些思想,但NeRF in the Wild本身是不能支持做Relighting的。而我们能够支持这个,即用户可以输入任意光照,例如一张觉得拍的比较好的图片作为参考,也可以输入一张环境贴图,也可以输入一个视频序列等来支持不同程度的Relighting。在这里面其实我们改了一下NeRF的基础结构,原来NeRF去做这个场景重建的时候,它其实一股脑地建在里头,不区分材质相关的、几何相关的、光照相关的信息等。但是我们因为考虑每张图的Lighting是不一样的,之前大部分NeRF可能假设它的光照是已知的,或者说consistent的。但我们面临的问题是说光照是不知道的,我从图片里面是不知道光照的,另外它不同图片之间的光照是跳变的,所以怎么办?我们想的办法就是显式地建模光照,我们通过一些技术手段去从图片里面提取光照的一些相关知识,然后用这种知识作为光照的一个先验加到MLP里面去指导后续的一些处理,所以在这里面我们提了一个叫做Neural Lighting Representation的概念,就是光照怎么去显式地建模,用神经网络相关的最新方法建模,大概是这样一个想法。具体地做法就是从一张图片抽取它的一个所谓的Neural Lighting Representation信息,这个信息里面涵盖了比如说太阳的位置、太阳的强度,包括还有一些室外天空的信息等,这边相当于是通过某种方式显式地建模起来,然后这些东西也会作为先验输入到MLP里去,可以分层次地把相关的信息呈现出来,最后能够得到一张图。它的表示是有语义的,它不是一个简单的latent code,因为没有语义的latent code是很难编辑的。所以我们去表示的时候会抽取一些特定的语义信息,之后去编辑的时候就很方便地改,例如太阳的位置、太阳的强度、天空的色彩等信息。然后这里的Neural Relighting是我们的一个核心,关键就是怎么去从图片中学习到它的一个光照表示,我们面向的是室外光照,相对来说这样的场景比较单一。我们前面从2018年开始做的很多光照估计的工作也启发了我们来完成这样一个工作。

我们看下现在做到的效果。这是用户输入的图片,完了之后我们可以把给定的光照条件迁移到这个平台上去,做到任意视角下的Relighting。可以改变光照、改变视角。Relighting工作的关键还是如何表示、处理光照。刚才介绍了我们NeRF方面的工作,也是我们组做的第一个NeRF的工作。
其实在做NeRF的过程中我也有很多的疑惑希望和各位老师交流一下。NeRF用了Ray Marching,其实这套渲染方法在我们做传统渲染的时候已经很少使用了,因为非常低效的。渲染中我们已经有一些更高级的方法,例如Delta Tracking,但是这样的方法目前在NeRF的领域好像还没用,之后其实是可以考虑一下的。因为NeRF既然是借助了介质渲染的这套方案,其实可以考虑用更先进的介质渲染的方法来加速或者提高质量。第二个其实我刚才也提到了,现在我们做渲染的话分辨率已经非常高了,1080p是标配。甚至现在有一些渲染的需求已经要让我们去做4k的分辨率。这个分辨率现在NeRF据我所知基本上是跑不出来的,就跑不出来一个合适的结果。所以NeRF怎么去支持这么高的分辨率,同时在这么高分辨率下做出高保真的图像,我觉得是一个非常大的挑战,这里面肯定有很多技术难题需要去解决了,我对这个方向非常感兴趣。第三个我想了一个比较大的课题,想问下NeRF到底是不是万能的?因为现在不管啥相关的任务都先用NeRF试一把,但是不是NeRF真的可以表示任意的一个信号。现在其实用NeRF表示需要考虑到算力的影响、存储的容量限制等。如果说在未来的某一天算力足够、存储容量也是无限的,是不是NeRF就可以表示任何信号,比如声音信号。因为我们在做渲染,除了我们做视觉渲染的话,其实还有一部分人在做声效的渲染,里面的Ray Tracing其实跟我们做光线的是一样的,那是不是NeRF可以来做声音呢?我觉得是很有意义的问题。所以我不知道这个NeRF现在是不是如此的万能,只要是信号都能表示,我想也趁这个机会和各位专家当面请教一下。
刘利刚(中国科学技术大学):这个工作中解耦时能保证光照正确吗?刚才看视频感觉光影好像有点不太正确。
过洁(南京大学):对,这一步确实不能做到足够准确的。我们也去调研了相关的方法,包括NeRF in the Wild,还有NeRFactor之类的工作,这些工作都会去重建光照,但其实它们其实没有特别考虑光照,所以重建出来的光照是非常奇怪的。我们一看这种光照估计用在传统的渲染包肯定是渲染不出来任何东西的,所以至少在室外场景上,我们现在做的是SOTA的。刚才刘老师提到说有些不是很精确,是这样的。但是NeRF好像确实不需要太精确,有的时候好像渲染出来效果好就行。
许威威(浙江大学):这个分解稳定吗?因为我看到分解出来的信息很多。
过洁(南京大学):目前还算稳定,其实我们在做分解的时候不是一下子把所有的东西分出来,我们是一步一步去分,先把光照信息分出来之后,这个信息作为先验再输入到MLP里面去,然后再把reflectance分出来,再把visibility分出来。所以就是说只要光照先验比较准确的话,后面基本上非常准的。这些模块是独立训练的,就是说我们给定一张图片,例如这里有一个光照估计的任务。
刘利刚(中国科学技术大学):我认为NeRF最终优化出的表达能力还是不能超过训练图片原始的分辨率。
周晓巍(浙江大学):我认为不一定。因为有多视角图片输入,视角之间的像素能互补。所以更高的分辨率是有可能做到的。
许岚(上海科技大学):我们最近的实验是在低清晰度的CT数据上训练,发现确实可能实现超分辨率的呈现。
韩晓光老师分享
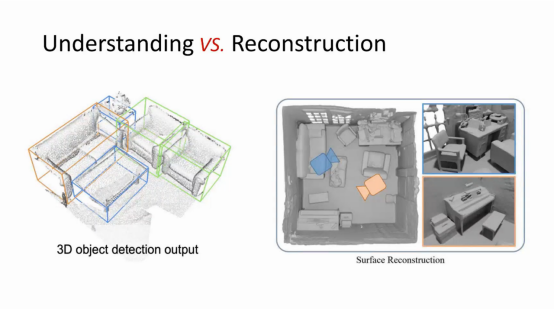
韩晓光(香港中文大学深圳):刚才听了很多老师讲Neural Rendering,我自己做Rendering并不多,我做Modeling比较多。我可能不想只围绕NeRF进行展开,而是想针对这几年Deep Learning for 3D 的发展分享自己的几点思考。第一件事情是关于 Understanding 与 Reconstruction 的关系,Understanding是Vision领域比较关注的东西,而Graphics领域的同行可能更关注Reconstruction。
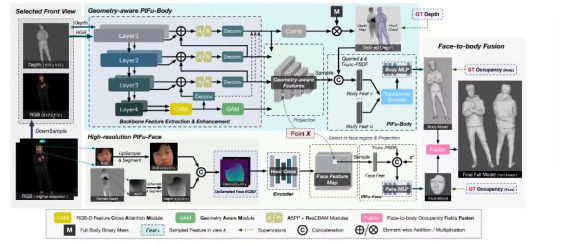
这个图的左边是比较常见的室内场景点云,围绕这个有很多做分割以及3D检测等理解类的任务。右边是关于重建的示意图,例如近年的像Neural RGB-D Reconstruction以及NeuralRecon等工作。针对目前这些重建工作来说,它们并不会去进行理解,不会去关心场景里面是什么物体。我个人觉得这两件事情应该是需要结合去考虑的。比如说我们最近这两年做的一些工作,例如Total3DUnderstanding (CVPR 2020) 是从单视角图像进行全场景的重建以及RfD-Net(CVPR2021)是从点云中进行重建,这两个工作都是先对场景进行理解,检测出物体实例,再对每个实例进行重建。并且,我们也发现理解可以帮助重建,而重建也可以反过来帮助理解。虽然目前的可视化结果还很不好,但我还是觉得我们应该是要这么去做。最新的我们ECCV 2022的一个工作,叫InstPIFu,也是从单视角图像进行重建,我们基于PIFu的思想,利用Pixel-aligned的特征,对于每个物体实例做了更加精细的重建,比起Total3D以及浙大崔兆鹏老师他们的Im3D(CVPR2021)可以达到更精细的重建结果。这也是我们在这个方向一直想努力的目标,就是提升基于理解的重建精度。
我们再聊聊第二件事情,也是我最近这几年一直在思考的一个事,是显式表示和隐式表示这两件事情,不管从Modeling还是从Rendering角度,两种表达方式其实并没有定论谁比谁好。接下来,我将围绕这几年我们在Modeling上面的一些工作进行展开。
我个人一直觉得要将Explicit和Implicit的表示相结合,这几年也围绕这个点做了一些工作。首先比如说CVPR 2022,做的是衣服的重建,叫REEF。首先对于衣服的几何而言,利用隐式表达其实并不是那么容易的,因为它并不是closed surface。当然目前也有一些工作,例如Unsigned Distance Field可以用来表达,但是UDF目前做的效果还不是很好。所以这几年关于衣服重建的工作,利用显式表达的还是会更多一点,如刘利刚老师和张举勇老师的BCNet (ECCV 2020)。而我们这个工作其实是基于隐式和显式结合的方法,我们首先构建隐式场并预先准备一个显式的网格模板,再基于隐式场作为引导去变形网格模板以拟合隐式场。

再比如,我们CVPR 2022的SharpContour,用来做图像上的实例分割的。在三维中的closed surface在二维中对应的是contour,而近几年基于Contour来表达物体边界以用于实例分割的工作也很多,例如周晓巍老师的DeepSnake(CVPR2020)。类似于三维中的surface,我们也可以用隐式和显式两种方式对Contour进行建模: 显式的表达是将Contour表达成Polygon,然后分割就是想办法对其做变形以拟合物体的边界;隐式表达,可以也设计一个隐函数,输入图像上每个点的图像特征,对其进行分类判断它是否在物体轮廓内部。我们这个工作也是类似,我们事先学习了一个隐函数,然后基于隐函数对一个粗糙的Contour(如可以是DeepSnake的结果)引导变形。这样的好处是,由于利用的显式变形,所以效率很高,又由于利用了隐式引导,所以精度也有保障。
另外一个基于类似想法的是目前我们一直在做的Sketch-based Face Modeling。我在博士期间做过一个DeepSketch2Face(SIGGRAPH 2017),当时采用的表达方式还是参数化表达,其对于人脸的表达能力还是比较弱的。在那之后,我们一直在想如何快速建模出具有更加丰富几何的人脸角色,如人脸上加上一个猪鼻子这种。目前我们发现基于隐式表达可以表达非常丰富的几何模型,然后为了做Sketching的建模,需要保障效率,这又是隐式表达的痛点。为此,我们在最近的一个工作上也利用了显式与隐式结合的思想。
最后一件事情是我去年年中的时候开始思考的一个事,大家现在做三维都少不了数据,不管是Understanding,Modeling还是Rendering。而NeRF可能现在还没有真正用到数据这个事,大家还是在研究基于Specific的场景如何进行优化,因此NeRF现在的一个非常重要的问题就是它的泛化性。再反观现在的三维数据,我们有ModelNet, ShapeNet 中合成的,也有 ScanNet这种真实的。但我一直在想,三维数据集里面真正有像ImageNet这样对应的数据吗?我觉得答案是否定的。我们知道ImageNet给视觉领域带来了非常快速的发展,包括现在大家一直在做的预训练自监督等等。我觉得,基于深度学习的三维任务,不管是感知还是重建,我们需要重新思考一下,如果没有类比于ImageNet这种数据,是否会阻碍我们的发展?
张举勇(中国科学技术大学):我觉得ShapeNet、ModelNet这种纯几何的数据集还不是最优的数据解决方案,还是要结合渲染考虑多视角的事情。
刘利刚(中国科学技术大学):数据集的label如何构建还需要深究。
许威威(浙江大学):我有一个显式和隐式结合的问题,比如sketch那个工作是有个base mesh,然后用隐式场表达deformation?
韩晓光(香港中文大学深圳):我这里只有一个隐式场,然后用base mesh做deform,相当于base mesh沿着法线方向走一个SDF值即可。
许威威(浙江大学):那隐式场用MLP表达,速度怎么保征呢?
韩晓光(香港中文大学深圳):我只需要query surface上的点即可。
刘利刚(中国科学技术大学):显隐式表达方面各有利弊,隐式表达能够保证不自交,但显式表达容易计算相关几何量。两者结合确实是值得探讨的。
刘利刚老师分享

刘利刚(中国科学技术大学):首先表达下我对NeRF的理解。图形学的初心实际上就是在建模和模拟我们的眼睛视网膜或相机成像的原理。视网膜的建模就是光栅,眼睛就是小孔成像,但人们对3D世界的表达一直都在探索。在几十年前,那时算力不够,在游戏中就使用一种称为Billboard的技术来表达3D,即始终是一张输入的图片,图片随着视点而旋转且始终垂直于视点方向。如果一张照片觉得挺假,它就用两张甚至多张,反正始终是就这么几张静态图片,跟着人转图片也在转,让人产生3D的感觉。后面采集的图像多了,算力也大了,发展出了Image based Rendering,通过多视点图片的插值来生成新视角图片。图形学从更物理的本质来理解3D,通过表达几何体上的点、纹理、Albedo、材质等,再加上复杂的光路去通过“渲染”计算生成新视点图片。另外还有基于Visual Hull的表达、表达人体器官及云雾的Volumetric Images等,再到现在的NeRF。所有这些技术的目的都是在合成新视点的一个图片,呈现出高真实感的图片。我理解实质上NeRF只是一种新的3D的表达,这种表达能够生成给定视点下的照片。
关于NeRF,我有三种理解和观点。一个观点是NeRF就是体素的图像,只不过是用MLP来连续表达。一个2D图像本身也可以用一个MLP表达,因为有一个UV就有一个RGB。当然一般不这样做,一般会用位置编码把高频恢复过来,所以图像也是个NeRF,只不过是单视点的。现在的NeRF只不过提供了更多的视点,如果都使用volume里同样的采样点来计算这些值,它本质上就是个volumetric的表示,即3D张量。比如TensorNeRF将其作为张量进行低秩分解表达。从这个观点来看,Mesh就是一个矢量的3D表达,NeRF是一个体素的3D表达,只不过是使用MLP的方式来表达。
第二个理解就是NeRF中color值存储了某点在光源下呈现的颜色,本质上是材质与光照的一个渲染结果,可认为是烘培(baking)结果。在游戏里面经常使用烘培纹理。只不过现在是烘焙到体素上,用MLP把它记下来了。因此,我认为NeRF本质是baked volumetric images。现在的几个NeRF编辑的工作的结果光照肯定不对,只是小范围的编辑人眼看不出来而已。如果要保证光照结果的正确性,就得将光照、材质等信息进行解耦,比如NeRFFactor这些工作,这时又回到了mesh重建方向了。
第三个理解,早年在图像分割中,像头发丝的硬分割不合理,就出现了软分割的image matting。NeRF中每个体素有density值,就是适合表达那种无清晰几何的、模糊的、特别像头发丝这种很细微的几何,因为它们在光的成像过程较为复杂,你一定要说头发丝的几何是1还是0很难说。所以,你要把它理解成很多层几何的叠加或混合,可以是基于体素级别的,也可以是基于多平面的或者多流形曲面的,每一层有不同的透明度。因此,我认为mesh适合表达光滑的manifold表面,而NeRF适合表达具有不清晰几何的物体,各有优劣势,无法相互替代。不能为了NeRF而去用NeRF去做一些几何的处理与应用。基于上述的三点理解,我们就能产生出好多想法。
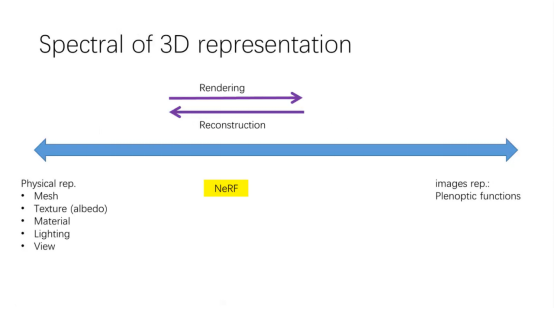
这张图比较好地展示不同表达的性质。在视觉领域,右边这个叫全光函数(Plenoptic functions),它什么也不表达,只是采集和记录在任何空间位置朝任何视点采集的图像,是一个七维或九维的函数(取决于算不算时间和波长)。这个图表达的是这个世界存在了,假设光源不动,或者光源动也没关系(处理时加个时间),我就在那个时间将点采集并全部存起来,这个函数叫全光函数,只不过现在叫全景图,它啥也不表达,就把点的属性记录下来。我要从任何视点方向来看时就去query它。而最左边的图表达的是图形学的纯物理的这个想法。有几何的点坐标、法相、纹理和材质等,加上光照后,经过一个复杂的基于物理的计算过程(光照的渲染方程)生成一个照片。所以我就只要控制几何、控制材质、控制光照,它就能生成真实感的图片。
这从左到右叫渲染,从右到左就叫重建,这中间指的是重建出真正的基于物理的几何。中间的过程就产生了很多不同的东西,你可以看我左往右走一点,mesh依然保留,但加入了View dependent texture的技术。我存的不是一张texture,我是视点相关的texture,这个叫View dependent Texture。如果还要求纹理是单一的,几何可以是View dependent的技术就是Visual Hull,所以Visual Hull就可能再往右移一点。NeRF是一种体素表示或者MLP,将材质和光照进行作用的结果存储了。所以中间往左走,刚才提到的光照解耦,实际上把NeRF再往左走一点,因为又有更多的理解了。如果要把材质解耦,应该也是往左走一点。可以看到NeRF在中间,刚好有左边的和右边的一些优势。现在很多工作像NeRFactor把几何、纹理、材质、光照全部解耦出来。右边这里还有Light Field以及Lumigraph等。所以,可以看到左边偏图形学的研究内容,右边偏视觉的研究内容,不过现在这两个领域融合得越来越深了,形成了一个大领域了。
基于这三个理解,我产生了很多新的想法。比如,NeRF的分割,因为它就是image,我就加上一些交互方法来做。然后基于这个想法,例如重建人脸,人脸是光滑的mesh,头发用NeRF,所以我觉得混合表达可能未来是一个值得探索的方向。还可以做baking,如果要把光源去掉,不bake直接的光源加材质的信息,那么bake什么?bake它的反射率,把lighting跟material不要耦合得太紧。这里可能就会产生不同的表达,这个表达是在我刚才这张图里面的往左还是往右?可以有不同的想法出来。所以刚才我有一个观点就是NeRF的分辨率为什么比不过?我觉得loss的计算还是同原图比,你loss那一项不等于0,就不可能超过它。除非你做更超分的NeRF重建,要用很大的MLP就有可能,所以我一直在琢磨这件事,因为我是从这些观点来理解NeRF的。
鲍虎军(浙江大学):NeRF本质上是volumetric geometry,是将原来layer的表示简化掉,思路其实是雷同的。
刘利刚(中国科学技术大学):为什么NeRF用体素表达是可行的?我的一个理解是好优化。以前MVS需要去找表面的点,是不可微的函数。
鲍虎军(浙江大学):是的,原来是不可微函数,一些特征点构不成连续空间。
刘利刚(中国科学技术大学):还有就是一个神经网络函数的表达能力的突破,能够表达任意维数空间之间的映射。传统逼近论里人工设计的很多函数,例如伯恩斯坦函数、样条函数、小波函数等都无法表达高维的函数使得在高维函数的研究和计算受限。
鲍虎军(浙江大学):现在用blend shape来做形变,表达形变是不够的。MLP这套尽管是个黑匣子,但让它学习,它能把一些信息记录下来,进而把一些东西表达出来。表达能力取决于函数空间。不过现在也面临一个程度的问题。如果函数空间本身不大,那么表达能力就不够。
刘利刚(中国科学技术大学):例如这张图中的一些细节就表达不了,mesh表达低频信息,NeRF表达高频信息。
鲍虎军(浙江大学):因为低频容易用低维空间去表达。刚才过老师提到的对音频或者其它信号的处理,这就像傅里叶分析一样。之后还有可能加上大规模数据库,例如对物体做分类,在NeRF中引入一些类别先验帮助其表达。
刘利刚(中国科学技术大学):但是这个layer没有语义,它是为了好优化所以把density引进来。这一点上我觉得它还没真正做到一个流形加上一个纹理。NeuS的工作也是为了便于优化。它都是在用先验,之前MVS就是对应点来优化得到正确的pose。所以我一直在想这个难度并没有降低,只不过基于NeRF表达的优化更好做了,或者更稳定了。
鲍虎军(浙江大学):这就是为什么它需要巨大算力的原因。
刘利刚(中国科学技术大学):巨大的算力要求源于“暴力地”引进多变量让它好优化。但是这个太“暴力”了,mesh的变量个数就是n平方级的,现在它的变量个数变成n立方级了。
周晓巍(浙江大学):对,就是说这种隐式表示例如NeRF之前的IDR,但那时候其实就优化不好嘛。NeRF的loss差不多和原来IDR一样,但IDR渲染的方式是surface based。surface based的渲染方式如果在空间中采样一个点,这个点离GT比较远的话就很难收敛过去。
刘利刚(中国科学技术大学):对,NeRF相当于每个点都试一下,你总会收敛到GT的点上。
许岚(上海科技大学):原来即便可微,它也很难收敛过去。当然NeRF前面的feature embedding也很重要。
刘利刚(中国科学技术大学):所以原来做得不好是因为空间不够大,还是不好优化?关于这个问题,我是这样理解的:输入图片无论单张还是多张,重建几何是一个欠定问题,即是一个多解问题。只不过我们一直在找所希望的那个解,但是有不同的几何、不同的材质可以生成同样的图片,无论渲染方程是面的还是体的。这个解虽然在那里的,但是不容易找到,于是发明了NeRF这种方法尽可能地去找合理的解。之前NeRF++那篇文章提出了一个radiance ambiguity的概念,几何是球,加上不同的纹理,它也能呈现出相同的图片。
鲍虎军(浙江大学):所以这里需要加各种先验以及各种约束。
刘利刚(中国科学技术大学):对,要么增加输入,要么增加先验,要么就增加 regularization做优化,所以我们的数学方法还是不够的。这是我的理解。
鲍虎军(浙江大学):求解上用更稀疏的方式来解,做出比较好的重建效果。另外一个是在函数表达形式不可知的情况下寻找解。从建模的角度以前我们为什么用各种各样的连续基函数去逼近一个复杂的形体,以前我们为什么要分片?否则的话这个参数维度就太高,函数的次数太高导致高度非线性。所以为了解决这个问题,用分片、用参数的形式以拼接的方式来做,这就是 CAD这么多年来走过的路。既然这个维度这么高,我干脆用一个更泛化的表达,或者说用什么基函数也搞不清楚(没有最好的基函数类),以前找了那么多种多项式,包括线性、非线性的,但都没有找到一个最优的。所以现在干脆就直接学出一些基类。
刘利刚(中国科学技术大学):但是基函数一多容易过拟合。我偏向把它大分小,这有点像样条,毕竟一个函数的局部是低阶的。
鲍虎军(浙江大学):其实像小波基,道理就是这样子。现在要在各种频段上去拟合,所以这个事情有很多理论的问题需要探索。
刘利刚(中国科学技术大学):我觉得Block NeRF是一种分块的方法,但它没有拼接,它只是分段的。拼接是什么意思?拼接是用局部基函数去构造一个整体,它的局部性自然是用基函数来体现的。我们现在Neural Network使用的基函数都是全局函数,无论是ReLU还是其它的激活函数。
鲍虎军(浙江大学):所以之后要看NeRF有没有可能变成分小块的,然后每一块是拼接而成的?这样计算量就降下来了。每一个局部区域都用一个低维度的函数去逼近。所以可能要对它的信号做一个理解。我觉得这个可能是一个方向。实际上回过头来就跟我们用样条建模型是一样的道理,它是有可能的,比如说这一块比较平坦,预测很容易,就可以用低维度的表示。也就是跟网络规模相关,相当于整个网络是自适应的。
刘利刚(中国科学技术大学):我曾经尝试过。一维的基函数好做,因为好优化,二维甚至高维就不好优化了,因为这时基函数一旦跑出去了,它回不来了。全局函数有个好处,无论跑到多远,它根据梯度可以回来,但针对局部基函数的性质,一旦跑出这个区间,这个区间就没有这个基函数了。
鲍虎军(浙江大学):就像样条一样,它的基函数有一个支撑域。但回过头来,用隐式的基函数呢?例如RBF这种。能不能一些用解析的表示,一些用MLP的表示?然后整合起来,想办法把支撑域外面的计算拖回来。就是要思考在其超出支撑域时如何把它优化回来。现在MLP算得太慢的一个原因就是我们把它看成同一个频段。
刘利刚(中国科学技术大学):对,事实上这个想法就是从B样条来的。我们去做逼近论,无论是多项式、还是傅里叶、或是小波的,都分频段的。你看大的函数是粗的,细节就叫做余项。
鲍虎军(浙江大学):一定是这样。如果比如说我在低频段,我就是用很低阶的MLP,规模可以很小。然后到上面频段越高,我觉得这个规模可能会很大,因为它有一个表达会更精细。我觉得这是一个比较理论的事情。
周晓巍(浙江大学):对,道理是这样,但是做不到。机器学习领域研究了这么多年,最后还是发现暴力的好用。
鲍虎军(浙江大学):我觉得我们所需的隐式神经表示与做识别、分类的机器学习方法不一样。因为如果用在一些规范的、很低频的目标,可能MLP网络真的不需要太复杂了。
许威威(浙江大学):但是其实做识别神经网络中用的也是CNN、Transformer,很少用MLP。神经网络的目标也可以认为是寻找如何寻找数据特征形成线性空间,从低维线性不可分变成高维线性可分。
周晓巍(浙江大学):对,但要看怎么理解了,例如重建视为空间的分割,物体里面是0,外面是1,那也是个分类的问题。
许岚(上海科技大学):positional encoding事实上就是升维了。
许威威(浙江大学):但positional encoding还是不够的,总不可能做个1000维的。
刘利刚(中国科学技术大学):好的,我再抛出一个问题。隐式函数80年代我读书的时候就有了。为什么到现在突然又火了?
许威威(浙江大学):我觉得这个问题的原因是MLP是自由的,什么函数都能表示。现在这么复杂的网络用以前设计的多项式表达不出来。
刘利刚(中国科学技术大学):就因为现在函数复杂度高了,所以火了?
鲍虎军(浙江大学):对,现在这个算力增大了,能表达原来表达不了的东西了。
许威威(浙江大学):原来RBF也是可以表达自由曲面的,但是阶数太高了,并且要用好多RBF混起来才能表达。
刘烨斌老师分享

刘烨斌(清华大学):首先介绍下我们做的几个事情,主要用NeRF来做数字人。各位老师都做了很多基于NeRF的数字人的工作。我个人比较看好基于NeRF的数字人技术实现数字人的形象生成。在这里还是要解决许多问题,主要是人头、人脸和人手几方面。我们今年CVPR在人体上做的一个工作是structure local NeRF。基于SMPL model,先在上面取一些关键点,然后将这些局部的NeRF合并起来,最后可以去生成这个人物的Avatar。现在的数字人Avatar技术还是非常重要,怎么去生成新的动作,怎么做到真实感更强。通过这种多视点视频的学习,可以通过一个骨架去驱动,最后在服装上产生一些细节。我们还可以结合手部的动作、手部的NeRF,最后合并起来做手的NeRF生成,脸部也是如此。服装方面,如果服装比较简单的情况下,目前可以做一些清晰度比较高的全身Avatar三维形象生成。在人头的NeRF生成方面,相对简单一些,因为人头的拓扑结构比较单一,现有数据量也比较大。不考虑复杂的头发和发型情况下,通过6个视点的多视点视频训练,可以生成一个惟妙惟肖的目标人物人头的Avatar,进而通过另外一个视频驱动,就可以生成人头的新表情新视点形象。当然,这里面我们加了一些超分辨的方法使得NeRF最终呈现的效果会更清晰一些。这种生成质量个人感觉可以在数字人场景有一些初步应用。在NeRF的人头生成和编辑上,我们也是做了一些工作的,包括交互式的3D GAN的人头生成,这里可以实现一个自由可编辑的3D形象生成,这种生成表示在做一些风格化的时候也是比较方便,包括可以做卡通化、艺术风格的生成等。未来在人脸、人体上,基于NeRF的方法的主要优势还是可以描述拓扑比较随意的一个object。
我们理解的NeRF是一个对三维场景离散的概率表达,而SDF或者mesh相比来说是一个确定性的描述,NeRF其实完全是依靠离散化策略猜测物体在空间中的表达。这种表达是比较离散的,它可以比较完美地拟合输入的视点。但是它最后可能会存在大量的噪声,因为它有很多解,这是一个从低维恢复高维信息的过程。它可以很好的逼近输入数据,但传统SDF、mesh的表达在优化的时候就很难非常准确地去逼近。对于静态重建来说NeRF可以给出一个比较完备的场景,它可以非常高效的去最大化地提取有关场景的信息。NeRF本身变化是非常自由的,因为它优化的自由度非常高。但现在很多工作是在NeRF上加上一个规范性约束,例如用三平面表达约束他,降低自由度。现在很多的工作在研究如何弄一个更规范性的表达。目前来看把NeRF结合得比较好的工作像Tri-Plane、UV,都可以针对NeRF太过自由的特性加上一些约束来进行规范化,使得求解变得更容易。当然也有一些是在三维上做的规范化,包括RegNeRF、Point-NeRF等工作。

很多同行认为NeRF跟传统管线很不兼容,这方面体现出劣势。譬如说多个NeRF如何结合,怎么在传统的CG渲染管线结合、交互编辑、渲染等。另外它目前的速度,虽然速度有Instant NGP、Mobile NeRF,但还是很难做移动端的高质量渲染。再者就是目前的分辨率较为模糊,没有分解出光照、材质,也没法做一些比较好的物理仿真。我个人感觉这些虽然是NeRF的缺点,同时也是学术界目前正在解决的问题。个人感觉NeRF不一定必须结合传统管线才有落地前景,我感觉NeRF本身可能是一个全新的架构,然后基于它去开发一些全新的应用。
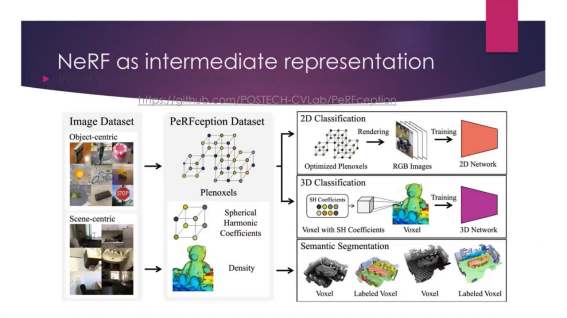
最近比较热的点还包括和一些大模型、语义相结合的NeRF生成和编辑的工作,譬如和CLIP的结合,基于Diffusion Model的大规模3D全视点生成等,也包括一些可以和语义分割一起去优化的NeRF,然后也有把NeRF作为一个中间的过渡表达,然后来进行各种三维场景的语义分割等任务。NeRF最大的特点就是说NeRF空间中每一个点都有一个density,density是一个连续的值。它本身就是类似二维图像Matting一样有个透明度而不是分割问题中的绝对0/1的边界。这个特点可以很好的和交互编辑结合起来。像这个工作,可以在NeRF上结合中间提取的这些soft feature,并进行交互的编辑,像图像编辑一样在NeRF上做编辑,例如在一朵花的一个地方改变颜色,这个变化能传递到整个花朵上,这应该也是它可以结合一些soft feature的好处。有soft feature这种好处之后,相比于传统的mesh表示,它最大的editting功能就是可以结合一些像CLIP这样的应用,可以通过语言来操控NeRF。这样的一些应用未来会比较火,而且也是NeRF区别于传统图形管线的一个新的交互方式。
刘利刚(中国科学技术大学):这里的规范化是什么意思?和mesh相比而言。
鲍虎军(浙江大学):因为NeRF是一种概率的表示,所以希望对其有一种规范,这样实际上在之后的处理会更精准。
刘烨斌(清华大学):加入更多的一些约束或者中间的表达过程。像人体,除了NeRF之外,还可以在Triplane,tensor,UV上做表达然后结合在一起,这样的话可以规范化整个NeRF空间,转变为二维图像上的学习和处理,学习速度更快,表达效率更高,因为原本的NeRF本身的空间太大了。当然,这些中间的表征方式太强则反而失去NeRF原来的自由度,比如用上人体SMPL的UV进行规范化,则目标对象仅局限于一些比较紧身的人体对象。
鲍虎军(浙江大学):因为它的分辨率不够、清晰度不够,所以这里你是用了超分的方法吗?还是那种传统的二维/三维超分吗?它会引发哪些问题?因为泛化性或者其它的不足,如果是把分辨率升上去会引发什么问题?
刘烨斌(清华大学):这里不是做超分,是在它中间的表达里用了UV。这里主要问题还是模糊,包括一些静态场景的NeRF也会建模出一些离散的、漂浮在外部的artifact,这里可以通过例如Tri-Plane或者UV的约束对这一块做refine。
鲍虎军(浙江大学):刚才人的运动里面你加了很多SMPL的keypoints,那么这个方案实际上是相当于用骨架去驱动LBS的时候,这种服装的形变会更自然是吧?这样做稳定性上会更好吗?
刘烨斌(清华大学):是的,这样的设计能解决裙子的一些问题。它在局部做NeRF,可以将整个运动比较好地分解。所以效果比较好。
刘利刚(中国科学技术大学):我这里再问一个问题,我对如何让美工创造NeRF打个问号。因为NeRF包括光照、材质等,如果不回到mesh,即回到本源,那么如何做创造?
刘烨斌(清华大学):我是觉得不跟美工结合也是一个应用的路线,而且完全基于NeRF。
许岚(上海科技大学):我想问个小问题。应用的过程中既可以结合美工,也可以替代原来的重建。在应用层面的话,假设有先后顺序的话,会是什么样子?什么会容易落地应用,然后什么会靠后?
刘烨斌(清华大学):我觉得现在数字人方面的应用是有可能的。大量的美工人员在做数字人。学术界做数字人也可以分为显式的和隐式的。隐式的数字人研究包括偏几何重建的和偏纹理生成的(NeRF)。未来数字人生成用隐式渲染的方式直接生成应该是有前景的,落地也会实现。另外,在AR通信,类似Holoportation以及Starline等应用中,通过隐式绘制实现是完全可能的。对这块应用来说,我觉得最大的问题是既保证高质量的绘制又能保证高效实时,是一个工程优化问题。当然有些应用还需要解决光影的问题。
刘利刚(中国科学技术大学):但我觉得这种创造物理上还是不正确的。就是还是无法做影视级的建模,因为有些人的眼睛对光影很敏感。而面向大众可以,这是我的一个观点,因为你这个光照是错的,通过GAN也是生成一个符合统计规律的模型,它不是物理正确的光照。
张举勇(中国科学技术大学):但是能不能通过GAN去学到所谓物理正确的一些规律。
刘利刚(中国科学技术大学):是的,可以用NeRF学到对光照感知的知识。比如光照可以估计一个,然后同另一个光照做loss,这个差异对radiance的改变能否可微地重构一下。
鲍虎军(浙江大学):对,我们是从绘制方程,实际上从计算的角度去做的。我刚才说的一个G-buffer,以后未来的芯片它要保持,这里有一个很大的近似,就是visibility的计算。从一个物体的中心去往外看、做采样,这里有个z-buffer。这里有有一个超网络去预测的。它可能是近似的,以一个中心向外做编码。
刘烨斌(清华大学):但传统的渲染管线不也是逼近真实的吗?
许威威(浙江大学):原先的渲染方程是几何光学,波动光学也没有涵盖在里面,例如衍射肯定是很难表达的。
鲍虎军(浙江大学):因为为什么我说这里有两个见解。Relighting还是从三维视觉的角度,它要去编辑、去模拟,从理论上它很难恢复出极高的真实感。哪怕我们用普通的方程去做,都达不到那一级的。它的自由度到不了,所以这里只能猜测看上去光影比较一致,视觉上ok就行了。我刚才说的从绘制的角度,实际上我们刚才说的用Neural那一套方式去刻画的话,它中间也是对绘制方式做了近似的,就相对绘制方程都不是一模一样。我们对visibility也做了很多精简处理,这个精简本来是一个物体,每一个点上都有visibility那根本来不及计算。所以我们是想把它浓缩成PRT,以物体为中心往外辐射,考虑从物体中心出发去做visibility的近似,所以这样把绘制的硬件以后可以降为z-buffer就行了,不需要shader其它的模块。
刘利刚(中国科学技术大学):是的,大概明白这个意思。有点像全光函数记录影像,而这里是记录的是visibility map。这里没有RT Core,保留少量GPU。
许岚老师分享

许岚(上海科技大学):我们上科大这边的话,其实也一直在尝试用例如NeRF这种隐式表达去求解传统的CG里面逆向和正向的过程,也不是求解,就是参与到这个过程里。然后我们稍微做一个展望,我们想做的其实是个称为NR-cube的engine。这个engine要包括我们的逆向的、传统的这种Reconstruction重建过程,然后要包括正向的Rendering渲染过程。此外,这个regeneration的意思是要依托场景去做生成。但其实生成本身到底是在对应我们CG里面的逆向过程,还是个正向过程,这是有很大的一个歧义的。然后其实整个上科大团队,其实一直都在推动整个NR cube的发展。为了做这件事情,数据会很关键。所以我们第一步是要依靠上科大一些光场设备,无论是multi-view stereo的Dome,或者light-stage这样的设备。本质上做这些事情其实就是想获得足够多的训练数据,以对Neural隐式表达起到一个更好的作用。

然后我们大部分的精力可能会就是专注在一个human centric的场景里,首先human centric本身是动态的,对我们去做一个动态为主的神经网络的表示、渲染的话是很有好处的。接着分享一下我们想做的一些基础的观点。首先是NeRF或者其它隐式表达可能代表着一个传统的CG pipeline之外的一种新型引擎。当然最早的NeRF表达可能训练起来是很慢的,但是它带来了很多的可能性,首先它是隐式的,网络BP可以很快,可以end-to-end BP。然后我们可以去捏造MLP里的feature,假设feature在一个很高维的manifold里,我可以去捏 feature manifold让它输出更好的几何、density以及纹理,然后支持一些下游任务,所有的这一切可能可以很好地并行化,放到包括一些cuda加速或者最新的ngp加速,进行更高效的运算。传统的MVS做不到这样得的一个灵活度,优化可以并行化变得很快。
像我们在今年一个例子上的实验做到单帧,然后用Instant NGP的方法去结合SDF,解出一个high-quality的几何。然后这是神经表示得隐式场在一个传统逆向过程的重建里面区别于原来MVS的很大的一个好处。当然它也有很大弊端,包括不像MVS一样对空间中很多更明确的、一些单点式的这种constraint,来约束做到很高质量的一些效果。隐式场其实可以有个很重要的过渡状态,很多时候其实我们不想它是一个 end-to-end的、不可解释的黑盒,我们还是希望它中间出来的东西可以传统的、可以压缩的、甚至拓扑一致的mesh。希望能有这样的一些兼容传统管线,包括blender、maya之类的软件之类的中间媒质,这可能是第一步。
第二步我们可能考虑像鲍老师前面所说的,我们要在在渲染方程里把MLP的渲染做进去,让它在渲染过程中都可以做到兼容,那就是对现有的一个CG rendering pipeline的极大的改造。但第一步我们可以先产生一些支持现有流程的pipeline,其实也是针对传统重建的很大的一个提升了。然后对渲染而言的话,其实NeRF有一套很好的渲染机制支持这种非常细节的、photo-real的渲染。一定程度上NeRF可以让我们摆脱传统的这种渲染流程的限制。像我们今年SIGGRAPH这个Neural Pet的例子,其实它是个一个CG的、动态的动物模型。早期也有一些工作是用CG渲染出来的z-buffer或者是前面的一系列buffer。现在把原来着色的这一步完全给跳过去了,并且还有一个好处是可以泛化到不同的动物动作上,做到可交互的实时neural pet渲染的效果。

许岚(上海科技大学):假设我们把NeRF作为渲染引擎,势必要做一些其它方法做不到的事情。首先是速度上,假设NeRF enable了一个快速的、甚至实时的渲染,很多事情就可以在这个基础上去做了,这个意味着网络是end-to-end 的,然后就可以把这部分的东西condition到某一些控制信号中,例如骨架。并在之后的流程中进行快速的操作。
鲍虎军(浙江大学):相当于预计算,后面会重用。
许岚(上海科技大学):是的,有个特别的地方是这个数字资产是正向渲染流程里的数字资产,不是从图片上恢复出来的数字资产。
许威威(浙江大学):就像现在Real-time GI里面一样,比如说Real-time GI里也是有一部分是baking的,不是动态的。动态的部分就把周围的光照baking到一个probe里面去,然后作为网络的输入。但是网络需要经过大量的数据训练。
许岚(上海科技大学):然后另一个想分享的点是对生成而言。NeRF跟生成的结合可能也是一个很重要的点。现在其实已经开始有很多工作做3D的表示,例如像刘烨斌老师刚才说的通过引入一些更强的soft feature去放到我的feature manifold里,之后可以做关于整个场景的三维风格化,这些风格化可以是由图片或者是其它各种各样的信息去调控的,包括CLIP或Stable Diffusion这样的生成模型去对接。一个浅显的任务是可以做一个3D场景的风格化,一定程度上也可以做到动态的场景。我们在实际的实验过程中发现了很有意思的一点,假设现在NeRF是个original的3D feature,我往动态做是引入了时间这个维度,然后每一个时间戳引入motion的这种变量。另一方面往风格化方向做,我也可以类似地引入到风格化中,然后把所有的风格化也像时间一样去做映射,所以做出整个动态的风格化或者是风格的切换,跟我在动态里面做的这一系列任务之间是蕴含一定的共轭性的。我们在尝试把很多3D往4D上做,然后把4D上面的很多东西又拿过来放到风格化里面去做。其实已经可以实现一些比较快速的风格化,这部分感觉还是蛮有意思的。
然后其实NeRF还有个很重要的事情,就是它一定程度上是把逆向过程跟正向过程混淆起来的,现在我们都看不清里面在做什么,其实它就是一个很“暴力“的、per-scene的training。我train出了一个feature manifold,这个feataure manifold一方面可以支持这个场景的高清渲染,像IDR一样。假设NeRF可以渲染出一个场景的、每个novel view下面的重建效果,那最笨的方法是我可以训练很多view,然后跑一个MVS,我总能把这个场景呈现出来。其实如果它能做到一个很好的效果,意味着我对场景先有一个很好的重建,然后这个很好的重建反过来又可以对我这个场景做很多、很重要的下游任务,这个是绕了很大一个弯能做的事情。但NeRF的话相当于在黑盒里end-to-end去做这个事情。所以也像刘利刚老师刚才说的,可能有很多任务不需要兼容传统的CG pipeline也能做,相当于是给NeRF引入了一些regeneration的新特性,这些新特性也许可以enable一些比较好玩的应用,包括对一个场景的快速编辑,以及可以形成一些新视角的渲染效果。
还有一件很重要的事情,目前这种生成模型可能跟渲染、重建很tightly couple在一起,假设我有生成引擎、重建引擎,那么可以把生成当做是一个prior,然后用生成的结果去guide重建。例如有个很好的人脸生成器,我现在输入单张图片我去做inversion可以快速获得它的几何。但是背后的原因可能是我生成的MLP这个框架里,我已经获得了人脸的很强的这种先验,包括semantic信息,所以可以很容易地把这样的一些semantic信息用到我的重建任务里。那反过来可以想象的是重建是不是也可以给生成提供一个更好的prior,我们现在做一些尝试是现在做full body的这种生成模型还是很难,但是full body中这种重建已经可以做得还不错了,像PIFu一样可以从单图片生成出一些很好的几何结果,但是NeRF的工作,例如EG3D或很多这种生成模型里,也许我density的表达是不够好的,因为它是一个per-scene training出来的,但multi-view的人体数据很难上升到像重建任务里on-the-fly的几十万张照片,几十万个mesh规模。这样的数据还是很难获得的。所以如果能把重建的这种prior应用到生产任务里可能可以做一个更好的3D生成.,这样的generation也是一个很有意思的事情,总感觉和reconstruction有着很密切的关系。我们也在做大量尝试,想把generation和reconstruction的过程设计的更加紧密一些。
然后另一个很有意思的事情是本质上可能NeRF是一个很强大的拟合工具或者表示工具,所以我们也尝试地在把NeRF用到CT和MRI数据中。一方面是做这种针对CT、MRI数据的超采样,这对提高CT和MRI这种设备的极限是很重要的,但这个难点是在于CT和MRI虽然都是一个volume的表达,但它的正向的成像模型跟图片的完全不一样。虽然也是个volume的slicing,但它的噪声模型跟图片上的这种完全不一样,噪声的模型机制也非常不清晰,导致我们在重建过程中关于噪声的考虑其实是比较困难。另一个有意思的事情就是可以用MRI和CT这种数据去辅助我们做更好的数字人,包括通过MRI或者CT得到内部的一些属性,然后我们可以把内部属性做成一种更好的参数化模型,去做这种精细化的手部、脸部的操控。然后一个很有意思的事情是我可以单独地把里面的每一个模态用这种NeRF的方式隐式地去表达。这也是我们想进一步把这种参数化模型跟NeRF隐式表达将内部、外部沟通起来,这是我们想往多模态方向发展的一个思路。
最后快速地讲一下现在我对CG的理解。我的理解比较粗浅,3DV就是从图片来、到图片去,从图片生成几何是一个逆向过程,而从一些几何的primitive,以前是mesh,现在可能是NeRF等各种各样的数字资产,虽然不知道里面具体是什么东西,但能够支持正向的渲染过程。然后假设我们管中窥豹地只看它的一个逆向过程,即从图片到几何。其实像刘利刚老师说的就是以前MVS有一个很系统的知识结构,包括很成熟的教科书,也有很好的论文。其实我们从2004年左右开始经历了一个20年左右的时间去雕琢我们的MVS技术,也积攒了大量的技术细节用于MVS里面。也有multi-view stereo以及photometric stereo等方面蕴含的算法,背后也已经有大量的、成熟的硬件,包括Light-Stage或者Dome的设置,它们已经可以帮我们拍摄大量的数据去做一些研究。然后传统的这种MVS的流程也已经非常成熟地应用在各种各样的CG和影视制作或者CAD的很多应用里,基本上支撑了我们上一个CG这种发展潮流里面的数字资产制作自动化的那一部分。这是我们用MVS的方法做的一些比较写实的数字人,其实MVS一定程度上也能做出目前NeRF做不了的东西。
对MVS而言的话,假设我们认为MVS是inverse过程中自动从图片产生一些数字资产的、传统的、很重要的pipeline。它其实在过去20年里已经变得很成熟了,有一个很重要的标志性事件是在去年,EPIC GAMES收购了CapturingReality,后者把MVS做成一个商业软件,目前在静态拍摄等方面中用得比较宽泛的商业软件。一个做正向渲染为主的公司买了一个做逆向过程的数字资产制作公司,这是一个很有代表性的事件。假设我们现在在做NR cube这个事情的话,也许对整个逆向过程而言我们目前还是处在一个发展中的阶段,也许我们可以有好长时间去打磨整个逆向过程。其实我们现在也缺少一些系统的,包括一些教科书级别的材料,当然我们这种研讨会已经是在努力地朝这个方向在推进了。我也相信很快能看到一些系统化的布局,或者是慢慢形成一些非常经典的模式。
然后如果要把NeRF在逆向过程中的应用提高到能产生一个像CapturingReality被收购了一样这种symbolize的application来证明它已经足够成熟的话,目前在NeRF上可能还有好多事情要做。首先是要跟传统的流程兼容,其次是假设我要把NeRF资产像传统的视频流一样推流并做云渲染之类的事情,它的一个codec的设计、资产的分享方式、加密需要考虑。这种codec sharing的方式都是需要进一步地去设计。然后还是以逆向过程为例,但其实正向过程相比逆向过程来说,对CG而言其实是更大的。在传统逆向过程中自动化制造的部分,最代表性的企业是CapturingReality。但是对正向过程来说,其实从市值上、从公司的成功度上看,Nvidia可能是更成功的。如果我们认为对CG而言逆向过程比正向过程更重要,那在逆向过程中应该要产生出一个跟Nvidia comparable的巨无霸来。但是其实好像并没有,最好的是CapturingReality,而且还被收购了。跟很多行业里的人聊,他们反而告诉我,在逆向过程里面其实可能只有20%是用CapturingReality做的,剩下的其实他们是想让artist去无中生有。例如artist可能先画出原画,然后从原画制作出一个3D模型,这部分3D模型其实是完全生成出来的。所以逆向的重建任务可能只解决了整个CG逆向过程里面自动化的那一部分,剩下80%偏人工设计的部分其实目前是空白的。
如果我们认为NeRF可以对CG有一个完整链条的革新的话,可能要在正向设计上,包括像鲍老师说的,我们要把它做到正向的渲染方程里,这就是从根子上去解决这个问题的尝试。在逆向过程中人工设计的那一部分,可能往生成路线上走是必不可少的。这样我们才能完整地用NeRF based的方法进行替代并有一个更上一层的思考,所以我们现在propose出一个NR cube的概念。对于这个,最后想来想去只有这句”路漫漫其修远兮“,我们可能要花20年甚至更长时间把implicit的这种神经网络表达从这里推动到这里。
鲍虎军(浙江大学):艺术家或者设计师们总是希望无中生有地modeling,但是反过来讲。他为什么都从头而来地建模。所以我们为什么不基于数字孪生去model、去editing?这能极大地提高效率。所以实际上我们要三维扫描,要做逆向工程。扫描了以后建个巨大的物体库,能避免从头开始设计。所以我是觉得实际NeRF很好地capture model,再做design,用这样的数据、模型。
张举勇:是的,DALL-E就是基于这样的目的。
刘利刚(中国科学技术大学):人的想象是无限的,所以DALL-E以及其它的都是限制在某个空间中去找解,就发挥不了想象力。包括就像Epic Game的MetaHuman一样的,对人脸或表情,形似可以做到,但是神似很难描述且难以量化做到。
许岚:对DALL-E这种模型简单套用到NeRF里肯定会有这样的工作出来。但是我觉得真正难的地方在于它得有artist的design能力。
刘利刚(中国科学技术大学):例如DALL-E这种模型能否做外插?
许岚(上海科技大学):它的外插会超出我们的常理,就好比它可以生成一头熊,也可以生成一只马,但它会无端地生成一头熊骑在马上。仔细想它没有超出computer science的理解范围。
许威威(浙江大学):我觉得artist的工作流程应该也是递进式的,而不是一把弄出来的。
鲍虎军(浙江大学):我也经常听到“不要这样的扫描数据“,但从头创造的效率是很低,建模速度是很慢的。所以这个事情我觉得他们最核心的问题在于不愿意去改变他们所习惯的东西。现在游戏建模型还是有一套流程,设计师实际已经有二维的艺术创作,然后用一个已有的雕刻流程把它建出来。因为那套流程他们很熟悉,你想去改变他们实际上是很难的。
刘利刚(中国科学技术大学):这种方向是不是适合走大众化路线,让80%的用户参与进来。
鲍虎军(浙江大学):现在很多应用不需要那么真实,例如有时候不需要把脸等物体做得太逼真。有的应用需要卡通化数字人即可。
张举勇(中国科学技术大学):我觉得这是不是有两个维度?有些应用是需要,但另外的方向可能因为没有人做过这件事情所以不改变。
许威威(浙江大学):我有个问题,即便把人建模真实了,其实场景什么的有时候需要是卡通风格的。所以还不能做成全场景、全链条的改造。
许威威老师分享
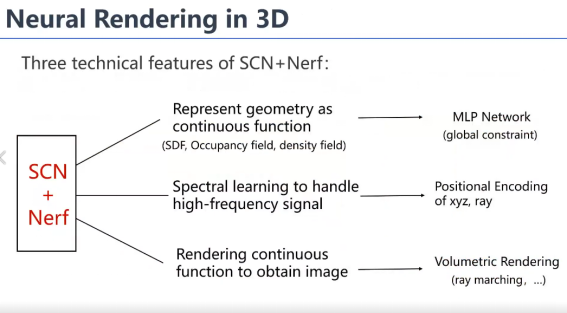
许威威(浙江大学):神经渲染我觉得它发展的一个目的,一个吸引人的地方,从vision角度来讲,它去隐式地建模场景的结构BRDF这些东西,所以不需要像原来图形学这么累,你要去把结构几何建出来,把BRDF要恢复出来,然后你才能够去渲染,它直接就可以端到端,就像我们以前image-based rendering的思路。所以我觉得它端到端的能力是一个很重要的吸引大家的原因。
第二个原因就是说,我们vision里面讲的generative modeling其实是一种采样,它这种采样就从一个隐空间下不停采样不停生成各种各样的数据,生成能力是受从数据学习到的模型的限制,其实跟我们图形学的创造我觉得是有区别的。这个是我个人的一个观点,首先我觉得它端到端的特性吸引大家去,那么其实neural rendering最基本的我们讲就说两种,一种是生成图像的,另一种是可以做到模拟三维效果,我们不叫它neural rendering,这个叫3D neural rendering,以示跟GAN之间的一些区别,其实就是用一个网络去表达三维的场景的结构和appearance。它的一个核心就是它采用一个三维网络去表达这个场景,所以其实是把各个view的信息整合到了一个网络里面去。这个网络渲染的流程大家都很熟悉的,用一个点进去query对吧?所以用查询得到的feature去渲染某个视点下的图片。那么训练的时候肯定是以带信息姿态的图片去训练的。所以整个来说,它其实是整合了这个multiview的信息。
总的来说,目前来说三点,第一点就是几何是用SDF等这些东西,用一个连续函数MLP去表达提供一个全局的约束,然后为了编码高频信息还是做了一个positional encoding。那么第三个就是为了用图片训练,它做了一个volume rendering,因为我们volume rendering把这个结构又恢复成图片跟图片去比较,这是它三个基本的技术特点。
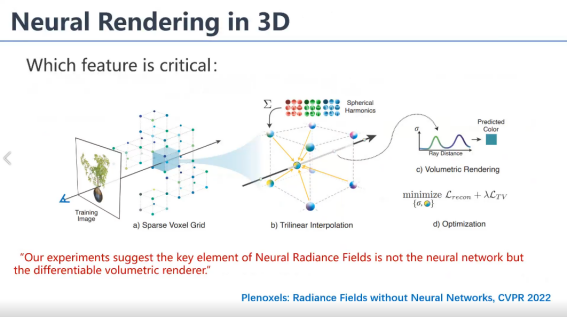
大家读过一篇文章叫Plenoxels就在讨论到底是 MLP的表达重要,还是这个volume rendering重要,它得出的结论就是后者。所以现在的优化其实很强的,它没有用MLP,它就用了一个稀疏的一个体素结构,而且它优化每一个体素里面的球谐函数,它直接就能把这个场景结构恢复出来,所以说volume rendering是最重要的。但是它这里面训练数据都是合成的,数据噪声比较少,所以可能MLP的global control能力体现就不够明显,所以这个时候你不用MLP,是可以训练出一个结果来的,但是当你的图像数据里面带着噪声的时候,其实我们也试过了,没有MLP,在真实数据上还是很难训练成功的。一方面相机有噪声,像素也有噪声,两个噪声可能会导致优化没有那么容易。如果说离散化的能直接优化成功,这个速度可以大大加快,MLP速度还是太慢了,所以说目前还是没有摆脱这个问题。
我刚才这只是讲一下 MLP,本身现在的NeRF rendering它是没有引入先验的,只是说图片直接去往里面比较。其实我们是可以引入先验去表达的,就跟刚才过洁老师那样,我引入一个先验从图像推光照,我就把它变成code就可以改光照了。这一篇文章它是加了一个先验,就是加一个depth,它是从单幅图里面去推它的深度和normal,然后就把这个加到训练里面去,那么就加了两个loss。我们先不管这个场景的表达,它导致一个结果就是我可以用很sparse的view,三个view我就可以把这个场景建出来,所以它融合multiview的信息的能力还是挺强的。我介绍它主要是想告诉大家,结合先验我觉得还是挺重要的一个事儿,否则你就是从头弄,我觉得很难加速。如果你没有先验,那就变成从头训练,从头优化就是会影响你的一些效果。第二个就是,你是可以去拿MLP这个基础表达去恢复原来的表达,我是选用了一个别的文章,这个文章建了好多的MLP,它优化的时候刚开始是用volumetric,当几何出来之后它就改用mesh。 这样质量会好很多,会加速。其实我感觉这结果是不错的,能重建出很多细节。我是赞成把NeRF倒回去跟原来CG流程接起来,你不一定说要摆脱原来的流程成为一条独立的流程,这个是两个选择。当然你也可以独立,就看你在不同的应用环境下哪个得到益处多了。但是,如果你想进入原来游戏的市场你就得和原来的CG流程对接。

下面讲一下我们这里做的NeRF的一些工作,因为我做场景做的比较多,是indoor sceen的。原来的这些技术做渲染的高光它都是有问题的,是有点散的,包括这个是去年的一篇siggraph, Indoors neural relighting,我们做的一个结果,这是去年那篇文章,这个是我们最近做的一个结果,就是高光是我们给合成出来的,包括场景的渲染。那么这个就是一个对比,你看包括这个灯,用其它方法重建出的它的几何其实是不对的。你看这个我们用两次MLP就表达了,就把它重建的还不错的,这个灯其实很高光。
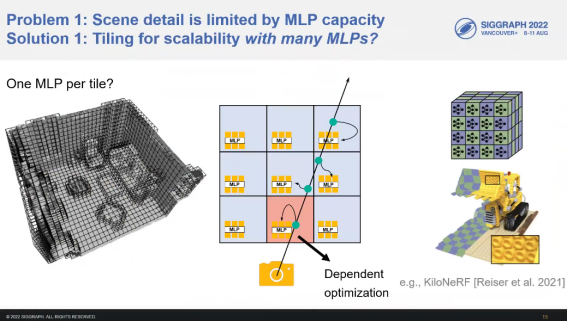
你整个大场景你可以用一个MLP去表达,一般来说这个MLP要么太大了,训练学太慢,要么就是它会产生很多artifact,因为MLP的表达能力还是有限的,加上positional encoding其实给的信息也没那么多,所以它会出现一些模糊。那么第二件事情就是,你在场景里面capture高光其实很困难的,因为高光是随视点而变的,视频它是非常高频的信息,你不可能真的那么密去拍高光,那么你就拍死了,做场景这么做是不大合适的,所以如果你仅仅是用原来的MLP去做的话,可以看到高光是重建不出来,因为高光没有view consistance,在 MLP上很容易被忽略掉。当然其实你可以拿它做去高光。那么,你一个MLP你每个点都去query,MLP越大计算量越大,所以这个速度也上不去。所以我们就把场景分了很多块,然后每一块一个NeRF,跟Block NeRF的想法很像, 其实我们投的时候Block NeRF还没出来,以前有个东西叫kiloNeRF跟我们是有点类似的。如果用plenoctree,它存储量太大了。
那么另外一种办法就是kiloNeRF,但训练太慢了。kiloNeRF是先训了个大的MLP,然后再去guide每个小MLP的训练。所以训练个大的开销你已经承担了,这个开销就很大。那么我们就是做分块MLP,但是它有一个问题就是一条光线可能穿过多个MLP,导致数据流特别复杂。你要把所有的数据都塞在一个GPU卡里才能训练。对大场景来说,那么多的数据那么多图片你可能塞不进去。所以这个问题它有很多的挑战。我们是做了一个解耦,给场景先重建了一个粗糙的structure,有一个大概的几何,不需要很精确,有洞也不要紧。
那么MLP训练的时候,我们就用MLP去预测它背景的颜色。我们预测时中间这些空间全部被略过了。因为我知道大概的几何,只需要在background预测几个点,所以说你每个MLP就不需要很大。我只需要这几个点,空间中其它点我不需要表达,所以NeRF就可以做小。这样就可以把训练给它并行化,每一块的NeRF都全部独立训练,这样你再大的场景没关系,我反正一块块全部给你分掉了。
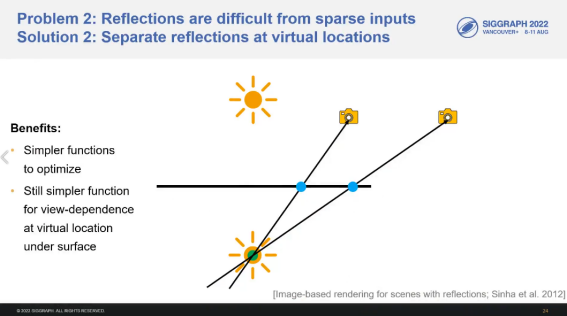
这个工作设计了两层的MLP,两层MLP中一层表达view-independent,一层表达高光。比如说你平面上有个高光反射,高光跟你的视点是有关系的,而且是一个高频的函数。但事实上如果你做一个虚拟光源的话,它就可以看成同一个虚拟光源了。两个图片它反映都是下面同一个虚拟光源的。我以平面为假设,因为在室内场景里面平面比较多,对于曲面只要你不要太凸或太弯就可以。那么这两个视点就可以认为是看同一个虚拟光源,就在第二层MLP表达。这个第二层我是放在表面之下的,用表面之下这个虚拟光源训练MLP,那么需要数据就很少了,因为这虚拟光源只要一张,我就能猜出来大概在什么地方。而且为了应对不一定是平面的情况,我用的还是SH,如果没有这个的话,可能重建效果就没有那么好。所以你曲面稍微弯一点没关系,它是可以重建出来的。我下面所有都是用一个MLP去预测它的反射,因为高光有时候很可能我拍的时候没拍到。在move的过程中,有的地方拍了高光,但某个中间这个点没拍到高光,完全没移到或怎么着的。所以其实也不是说没拍到,但它本身跟太相交的一些图片,光线可能就没有高光信息,但是你视点移动过去是一定会有高光,一定会穿过它的,所以你不共享的话高光信息会被漏掉。但是它们都可以认为是在看虚拟光源,所以我们就用虚拟光源模拟高光的移动了。渲染的时候,我们这个是做到了1200×1080的分辨率,但后期还是有一个网络。我们这个网络不是增加分辨率,是提高它清晰度的,因为这里可能会有些artifact。我们渲染上也做了一些操作,我是把它view-independent部分是用plenoctree来编码的,高光的部分是用CUDA MLP来渲染的,因为baking起来数据太大了,所以我在渲染加了个速。
这边再简单介绍一下另一个工作,其实是PIFu的一个扩展。所以讲这个,是觉得现在MLP还是应该接一些先验的。就是说接一些先验之后,第一个就是可以直接生成,应用的时候直接forward就行了。第二个,我这里是在PIFu里面加一些depth数据,发现它的稳定性高了很多。我们训练时候,比如说我们是这种模型,穿个裙子衣服脱下来什么,重建出来也没什么问题,就是成功率大大提高了。那么这里我们做了两层表达,我把人脸人体分开表达,因为想把人体建的细致一点。原来PIFu人脸做的不好, PIFuHD又不够稳定,经常会出一些奇怪的东西。我们这里用了三个view,一共用的三个view的depth,然后做了一个multiview的融合,下边是对人脸detect之后专门对它做了一个操作,最后融合在一起。整个网络跑起来是大概一秒能重建出一个人体,但这个人脸的几何还是不够好。所以我觉得NeRF加先验还是有必要的,要不然整个的优化会很吃力。其实我个人还有一些简单的想法,我是想把这个neural rendering当成一种image-based rendering来看的。我承认它是建了一个场景的表达,但我认为它最初的目的是image-based rendering建的,所以我一直是把它当成一种image-based rendering技术来看的,不管你说你后面加condition做动态什么的,本质上它还是为rendering建的。所以我是觉得很多编辑和参数化的Nerf模型虽然看起来也有一定效果,但我很怀疑它们将来往上能做到什么样的程度。
刘利刚(中国科学技术大学):就是说传统的渲染方程是可解释的一个函数,你这个是不可解释的一个函数,但是生成像就行了。
许威威(浙江大学):做image-based rendering是可以的,但是如果说要拿它做那种解耦编辑之类的,我觉得还不如传统管线,不如把利用NeRF得到一个初始表达,然后倒回去转成mesh和材质,转到传统流水线去。因为传统那一块渲染编辑功能比较强,否则我觉得你要在NeRF上做这样的一个表达,我不知道它的上限在哪里。
刘利刚(中国科学技术大学):如果网络足够大,是不是一定能逼近真正物理的?
许威威(浙江大学):但网络足够大的前提是你要有足够的数据。就像你做参数化模型一样的,我觉得现在NeRF、MLP是有一点参数模型的感觉,加condition其实就是给它加参数,你不可能把所有的参数都加进去。我是指NeRF这种表达MLP的表达编辑的上限,因为毕竟还是一个函数的表达,你不可能把它所有的参数都输入到这个模型里去,所以它表达一定是有上限的,或者你为这个应用做了一个编辑,那另一个场景又做不了,你为这个场景做了一个参数化模型那个场景又用不了,就会出现这样的一个情况。
张举勇(中国科学技术大学):其实可以跟传统的可解释的可分离的模型结合。
许威威(浙江大学):对,所以我的意思是说最后你应该把它倒回传统表达,就相当于以它为基础构建以前的表达。就像刚才那篇文章一样,它以MLP为初始,但最后结果给你的是网格和material。
张举勇(中国科学技术大学):就这种正向的和逆向的,结合肯定是必然的,我觉得大家可能都同意这个观点,就看要怎么结合。
刘利刚(中国科学技术大学):我不同意端到端,现在的是neural rendering,从这到那全部替换掉。我就说端到端有点暴力了,因为rendering那是有物理含义的。
许威威(浙江大学):所以我就是这个意思,我说大家如果在MLP上去探索编辑,始终强调MLP一直要存在,但是它的边际上限在哪里?我是在问这个问题。
许岚(上海科技大学):有很多那种编辑的工作,如果一个场景有很多MLP,它可能是MLP之间的一个排列组合。如果一个动态场景是个MLP,我可能MLP表达是canonical model,然后后面有个deformation。
鲍虎军(浙江大学):它可以把各种属性的参数建一个MLP,每一个是独立分离的。有这个东西你可以用隐式的NeRF去guide,然后直接去操纵显式的,这样就会有机地去整合在一起。因为显式它对用户的交互比较友好,隐式它又对连续性的保证比较好。可能你要设计出更好的 UI,更好的计算策略,让它去快速的逼近。一定要把它分解,逼近的时候一定要参数化。参数化以后,因为你要迎合传统的调控,比如说我材质反射率、BRDF、光源的位置,你不把它解耦,你做不到那。这样你才跟传统的,它的几何、各方面的应用是相关的,现在的NeRF是整个耦合在了一起。
许威威(浙江大学):对,虽然你可以输入condition,你只要有数据就能训练一个模型出来,但是感觉很孤立,我训练模型只能干一件事情。
刘利刚(中国科学技术大学):我觉得端到端还是太暴力了,实际上你要把中间分解。
张举勇(中国科学技术大学):但是我觉得现在已经有融合的趋势了,有很多工作现在也在融合,做editing。
鲍虎军(浙江大学):因为它原来是耦合在一起,维度很高,所以你刚才这个工作是从空间上把模型规模降下来。另外一个是在变量的维度,刚才高林老师实际上是从属性上把它解开,所以它最后都是为了加速或者更好地控制,因为你越小越好控制。
周晓巍老师分享
周晓巍(浙江大学):从我自己研究的角度来说,NeRF也好,NeuS也好,这种隐式神经表示,主要还是给我们image-based modeling提供了一种新的表示和一个新的解决途径。其实就回到了昨天我们讨论了很久的问题:比MVS好在哪? 我们可以看到以前的重建流程还是比较复杂的,有很多单独的步骤,流程比较长,所以导致整个的鲁棒性比较差。我觉得像NeRF和NeuS这一套,它主要是鲁棒性的提升。虽然有时候精度可能在某些地方还比不上MVS,但整个的鲁棒性很好,可以让整个流程变得高度自动化。原来为什么不行呢?因为原来每一个步骤都有hand crafted步骤,然后整个流程不是可微的,所以没法联合的优化,这样的话没有一个反馈的机制。基于隐式神经表示的话,无论是表示方式还是rendering的过程都是可微的,所以现在整个重建的流程就发生了变化,我们就把它变成一个优化的问题。优化的过程,就是回过去捏网络的参数或者feature,就有点像我们以前手工建模,对着一个图像,不断的调,直到跟这个图像非常像。其实现在这一套有点像用机器来代替人工的建模。
相对于传统MVS,我觉得用一句话来说,就是通过这种新的表示方式,可以把重建的问题转化成一个全局优化的问题,并且优化的目标函数就是渲染的质量或者真实感。这样的话首先鲁棒性提高,少了很多人工设计的环节。第二个就是优化的目标,就是逼近真实输入图片,所以从rendering的角度,从视点合成的角度,它的效果比以前更好。
传统的表示方式,基于mesh也好,或者基于voxel也好或者什么,其实也有很多人试图去做这种基于优化的重建,或者用这种differentiable rendering去做,但是为什么之前做不好,而现在用这一套隐式神经表示可以做好?其实就是因为这个表示有很多好处,从重建的角度,从优化的角度它有很多好处。首先它是连续的,表示是连续的,非常灵活,什么东西都能用同一套表达方法去表示。无论是geometry,color,甚至illumination,虽然不是基于物理的,但是它可以把这些变化用一个code去表示,作为网络的输入。所以它在有些时候可以建模非常复杂的一些因素,甚至可以表示semantics。另外它现在很好优化,它本身是一个连续的。其次很重要的一点就是volume rendering会有利于优化一些,因为它rendering过程比较简单,就是一个线性的方程,导致loss function本身就会相对好优化。其次就是我们所说的网络的inductive bias,MLP它是一个连续的函数,所以可以保证整个场是连续的。

那么接下来就举几个例子,我们最近的一些工作。第一个就是跟NeRF-in-the-wild很像,所以我们自己叫NeuS-in-the-wild。 NeRF-in-the-wild做的是novel view synthesis,我们这里还是希望从大量的互联网图片重建出几何。其实以前MVS那一套也做过,叫做Building Rome in a Day,但只能出一个点云。对于这种互联网图片,因为它光照变化或者视角变化都比较大,所以直接跑COLMAP很难得到一个干净的几何。但是现在用NeuS这一套的话,就可以看到重建出来的连续性,光滑性是很好的,虽然细节有些丢失,但从互联网图像的角度来说质量已经挺好的。这里能做出来的还有一个原因是我们可以表示光照变化,就像NeRF-in-the-wild。
刘利刚(中国科学技术大学):但你这个pose还是要精准?
周晓巍(浙江大学) :pose 还是要精准,越精准越好
刘利刚(中国科学技术大学):你跟那边的NeRF-in-the-wild有什么大的区别?
周晓巍(浙江大学):主要区别是这里的目标是几何重建,另外就是sampling的方式上效率上会好一点,用粗糙的geometry引导采样,所以能够让重建过程中采样效率变高,满足这种大场景重建需求。
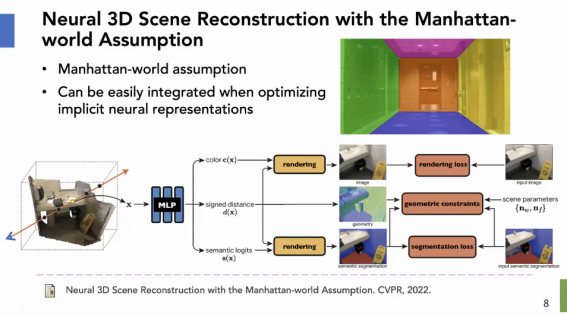
第二个工作我想说明隐式表示很容易加先验,这是我们今年CVPR的一个工作,关于室内场景的重建。其实现在用隐式神经表示,从图像去重建室内场景还是挺难的,因为室内有很多没有纹理或弱纹理的区域,直接去做的话结果就会非常差。其实室内有一个很好用的先验,就是这种平面。或者我们叫曼哈顿 Assumption,尤其对于人造的室内结构。就是各个大的面基本都垂直的。这个约束条件在计算机视觉里面很早就有人用,但是以前在MVS的框架下,为什么用不好?这是因为MVS它是以key frame的depth为表示的,我加先验其实只能加在那些key frame上面。但是后面还有一个融合的过程,很难保证它们的一致性。也就是说以前MVS的框架里面,我这些平面的约束只能加在一个个深度图上,很难加在一个全局的三维表示上。但现在的话,因为整个MLP的表示它就是一个全局的表示,平面的约束就可以直接在3D空间里面最后出的geometry上面加,而不用在每一个视角下去加,所以它一致了,并且很简单,就是把MLP出的SDF,求导后得到它的normal,直接在normal上面加了一个全局的约束。
另外一个例子就是对人体的建模。这个是Neural Body,我们去年的工作,从稀疏的相机拍摄的视频去恢复一个动态的人的NeRF。以前对人的重建基本上还是MVS那一套,因为很难去利用人体的先验,也很难去利用时序的信息,它基本还是当成静态去做的,所以需要大量的视角去拍摄。那么现在用神经表示这一套,首先可以引入人体的一个先验。其次可以利用人的运动的先验,整合整个视频里所有帧的信息。比如Neural Body的做法就是假设每一帧的神经辐射场都是同一组隐编码decode出来的,而且这一组隐编码它贴在一个参数化模型上面,会随着每一帧人的pose不一样,编码的空间位置也会发生变化。那么这样的话,就可以用同一种隐编码去表示视频中所有帧的一个人的NeRF,那么就可以利用视频中所有时刻的观测来做一个更好的重建,这样的话也可以减少每一帧的输入视角数。另外,因为隐编码的空间位置跟参数化模型一样,也相当于用到了人体的一个大概的几何先验。所以,用神经隐式表示这一套可以很好地加一些重建对象的先验进去。

另外就是的今年Siggraph的工作,我们把neural body扩展到了多人,其实也很简单,就是每个人建一个neural body。但是这有一个问题,如果多人去这样做,还是需要分割。因为要训练多个neural body的model,得知道每一帧里面每个像素对应到哪个人。但用一个预训练的分割网络,在这种多人的有遮挡的室外的情况下,其实很容易出错。怎么做呢?这里的一个关键就是,每个人是独立运动的,它跟背景也是独立的。基于运动不一样,我们可以把他们分开。所以这里的关键就是说,我也可以用网络在3d空间里面表示每个点它属于哪一个(部分),然后去同时优化多人的 NeRF,以及每个点它到底属于哪一个人。因为motion不一样,每个点只能被一个人表示,所以这个也是可以一起去优化的。左边是我渲染的结果,右边是Mask,这个不是用预训练网络割出来的,是优化出来的,可以看到mask其实是很精细的,甚至比手标的可能还要精细一点。

所以这个例子我想说吗明,在很多时候,如果我们对场景能做一个这样的重建,其实对我们AI的算法也很有帮助。比如说我们重建很多这样的场景,就相当于免费的得到了很多人体的mask标注。所以我觉得NeRF或者NeuS这一套有一个潜在的很重要的应用,就是给AI提供数据。现在像NeRF这一套,它本身建模是从真实的数据来的,所有最后合成出来的东西会比较真实,这是第一。第二就是它可以基于这个去生产很多新的东西,比如说生成新光照,或者生成新的一些场景的布局等等。第三个如果在重建的过程中还能得到一些free的label,那就更好了,就不用标了,所以现在很多做无人驾驶的在关注这一套,希望能用这个来生成大量的训练数据,或者创造一个高真实感的仿真,来帮助训练AI。
最后,我自己最感兴趣的还是动态场景的表示。现在基本能做的主要就是人,因为人有比较强的先验信息。对于更通用的场景,我能不能把NeRF这些表示扩展到4D,其实我觉得现在还没有答案。这里有一些需求。首先,就是它不需要一个很强的先验可以表示任意的对象,比如人、物体、背景甚至流体气体。第二是要有一个很好的压缩率,最早的free viewpoint工作就是用multiview的video去表示,那个数据量太大了,它没有一个很好的压缩的效果。这个压缩率很重要,一是从应用的角度来说,我们无论存储还是传输一个3D的视频,这个数据的大小都是很重要的。另外如果可压缩而信息又不损失的话,就说明你这个表示很精简,说明我们还原或者重建表示的时候,也可以用稀疏的观测。这个就跟以前压缩感知是一样的,只是以前压缩感知模型太简单了。其次,就是能否实时渲染。最后,就是如果能够编辑就更好了,但这个可能更难。
问题:为什么NeRF这种引领性的工作都是国外的学者提出来的,然后我们的国内的研究者更多的考虑的是应用。
鲍虎军(浙江大学):我觉得我们的文化,是一个比较缺乏一些深度思考的类型。因为大家可能面临着各种各样的压力,所以很多项目都是比较短期的。因为做这些很深入的问题,基础性的问题,你这个环境你的考核根本不允许。尤其这些大量的研究,实际上都是年轻人在做。年轻人现在都有压力,可能引发了大家都想走快捷的一些研究,我觉得这是一个普遍的现象。
另外一个,我们缺乏非常深入广泛的交流合作。你看NeRF那篇文章的作者跨度很大,有做三维很牛的,又有三维视觉三维图形,还有机器学习,那几个老师是真正的横跨这三大领域的,是一个真正的交叉合作。我们整个中国社会的这种文化,我们的制度现状,导致我们缺乏真正的实质性的,围绕着一个问题去思考去合作。你看我们现在反而跟国外的合作比较紧密。从某种程度上,从大家的表现来看,我们做世界上最顶尖引领性的研究问题的能力是具备的。但是我觉得更深层次的考量,就是我们要真正地合作。因为这种交叉的合作就是要相互信任,相互欣赏,而且相互深入地交流,让大家相互理解,从不同的角度去研究。
刘利刚(中国科学技术大学):放在更广的层面来看,中国在前面40年都在求生存、求发展,都在赶超。直到昨天我看到一个新闻,美国众议院声称中国已经不是发展中国家了。所以说我们已经跨过了这阶段,就能更自由地,能够不为生存而去过多追求短期目标了。NeRF为什么都是出现在大企业,像微软这种,因为他们就没有为了上项目。谷歌研究团队根本就不是为了商业化,他可能是从一些商业一些项目中慢慢提炼到研究院。因为我跟许威威老师在研究院都待过的,真的不用操心填表,去算什么绩效的繁琐的事情,我们整天就在琢磨研究上的事情。
因此,我就把它总结两点,一个是土壤,我们需要构建让研究者能够安心、扎实地从事科研的土壤。只要有合适的土壤,总会激发各种种子结出好的成果,这个需要有个过程。中国人也搞出了像ResNet这种广泛影响的工作。第二个就是机制,我们很少去真正围绕项目的目标不断讨论与合作。但现在的制度,排名单位第一作者给0.8分之类的?这样大家不鼓励合作,我觉得不对,这种机制一定要改。但是学校没有别的政策,没有别的策略的情况下,还是只能算算绩效。比如两家单位合作,如果没有一个合理的评价机制是难以长久合作的。
另外还有个因素,就是一定要长期围绕它去思考,因为有些东西不是想一天或者短时间就能想出来的,天才也是需要一定的积累才能爆发出闪光的灵感的。
许威威(浙江大学):我觉得要建立一个credit的共享的机制,比如说大家共同讨论的事情,我们应该有共同的纲领,所有人名字都得在上面。因为我觉得国内对知识产权的尊重是不够的。当然这是个文化,不是说法律规定你一定要提我。我觉得国外这些做得很好,比如我的合作者是谁,你在你的talk前面你就必须列出来。在国外,比如你写survey,如果你做的不好,那是会起到副作用。你如果对每个人credit承认的不够,对你是负面影响的。所以一般年轻人不敢写survey,怕得罪人。我们国内在这方面欠缺我们圈子的文化,没有建立那么好。
周晓巍(浙江大学):我个人感觉创新也好,合作也好,很多时候还是要来源于一个内在的驱动,就是做这件事情的时候,是内在驱动的,就是对这个问题特别感兴趣,我每天就想着怎么解决它。那么无论是创新也好,合作也好,都很顺其自然的,因为我想把它解决,而不是说为了发一篇paper,为了评一个职称,不是靠这种外在驱动的。我觉得国外很多人做研究确实是这样,就是感兴趣,能把这个问题解决了就行。
许岚(上海科技大学):我是很期望有这么个状态。我做这个事情是我最感兴趣的,然后他们居然给钱让我做这个事情,然后我做出来之后他居然还花钱买。如果进入到这个正循环的话还是很好的。
问题:抛开Nerf不谈,NLP以及视觉领域的发展给图形方向带来的启发是什么?
韩晓光(香港中文大学深圳):首先,视觉的很多发展也是从NLP启发来的,可能也是因为NLP的数据更容易获取,视觉当然问题会更多。现在这两个领域相对图形学来说发展要快很多,比如说我昨天讲的NLP以及视觉现在在讨论大模型这个事,但是图形还没发展到这个阶段,就连数据我觉得都还没有well-defined。图形现在好像还是在讨论表达的问题,它可能表达很多,NeRF也好,隐式也好,Mesh也好。所以我们是否需要从其他领域借鉴,想听听各位老师有什么看法?
鲍虎军(浙江大学):我觉得两个使命目标是不一样的,图形学它实际上是模拟仿真,你可以把它理解成从计算的角度,从科学计算或者模拟仿真的角度,它出发的目标就是无中生有。但是为了提高效率,提高图形绘制的质量,有的时候我们需要从现实的环境中去采集重构这种东西,所以引发了我们为什么需要从视觉、从NLP其它方向来。但是图形原来更侧重于三维的一些对象的表达,比如说现在大家在做人,人就一定涉及到语言、感知的问题,在这里面就会借鉴很多其它领域的方法。所以图形里面的数据集,实际是上因为AI领域它更多地需要数据驱动,它需要那些数据,所以两个方法论在根本上是有一定的差别的。
但是AI也好,NLP也好,视觉也好,这种智能的技术一定会给图形带来一些变革性的变化。因为这个世界本身就是跨模态的,你这种跨模态的智能技术未来真正地会促进图形的一些变革。这种变革可能就是我们怎么求解图形这种确定性的优化问题,这可能带来一个很大的变化。包括现在很多人说transformer很好,在图形里面到底怎么用?我觉得直接套用是有问题的,但是它有很多的思想在里面。包括刚才你们建的那种数据库或者数据集,在图形领域的数据集,未来我们可能也会借助于数据驱动。这个数据集怎么来建,可能跟视觉那边还不一样。所以这个事情我觉得方法论上一定会借鉴的。还有一个,图形反向的对视觉领域的影响,二者我觉得可能慢慢会融合,慢慢会相互地促进。
刘利刚(中国科学技术大学):我个人认为,任何计算任务的本质,可以抽象为两点,一个是数据的表达,第二个是计算方法,即算法。你看NLP、CV等领域处理的数据大部分是结构化的、具有线性结构,表达清晰简洁。而图形学中研究的3D对象的表达至今仍没有统一的表达,出现了包括点云、网格、有多视点图像、深度图像等表达方式,这就导致了基于不同的表达有不同的研究思路、研究手段、方法论,研究被分散了,没有统一的研究框架。如果NeRF是一个统一的表达,它有优势cover住别的东西,慢慢的数据集也开始有了,研究者的方法论也可以集中,一些方法就可以用上来了,是不是可能产生一个突破?
鲍虎军(浙江大学):我理解,你们觉得NeRF或者是别的东西以后一统表达三维。我觉得NeRF还达不到,当然有可能以后有一个上帝的表达方式吧?
刘利刚(中国科学技术大学):我认为,表达不一样,且非线性结构,就造成研究方法的困难和分散,还有就是数据集不够。第二个观点就是研究门槛过高,我们需要降低入门门槛,让更多人参与进来,人多就更容易产生好的工作,总会有一些好的工作能够冒出来。还有就是研究与开发框架,GAMES我们也准备推40系列的程序开发框架,让同学们更容易上手。
张举勇(中国科学技术大学):我觉得是不是领域不一样,他们可能更偏AI,我们这个偏计算一些,只是我们会用到一些AI的技术。但从另外一个角度,比如基础数学或者图论,做的人更少,但是他们那个领域也不要很多人去做。我们这个问题的定义上面,是不是导致我们也不需要那么多人?或者说他们的范式、研究的类别是不一样的。在外人看来CV和CG是很靠近的,但是我觉得一个是偏learning,一个是偏forward的geometry modeling的computation,我觉得还是跟机器学习偏的有点远。
许威威(浙江大学):对我补充一点,我对视觉的感受,它都是传感器来的,所以数据格式相对会简单一点,但是它后面为了处理也发展了各种各样的格式。最早我们是用点表达。到MVS是把它提成feature point,稀疏地去表达,到CNN再去提dense feature。我觉得表达是一定会多种多样的,因为你每个任务都需要根据自己的特性去处理,我为了完成特定任务一定要把数据处理成这个样子。所以我并不认为视觉的表达是单一的。
第二点就是图形学跟视觉差别是很大的。我们刚开始是做正向设计的,我们光样条曲线曲面就发展了那么多种对不对?所以我觉得它的表达那么多是因为它跟任务相关的。而且我觉得图形学的产业是不小的,Nvidia市值就很大,虽然说有一部分是因为AI起来的,但在AI之前Nvidia的市值就很大,就是我们从图形学的公司来讲,并不比视觉公司小。视觉公司现在有哪几个?微软,Google这种大公司它不是视觉起家的,唯一的可能就是商汤上市了。所以我觉得图形学已经孵化了很大的产业了,只不过这几年我们国内在正向方面做的不够好,导致我们这个产业是落后的。其实正向设计市场是很大的,你看GTC的演讲,黄仁勋认为正向的市场是更大的,因为人类是要设计的,是要往前行的。当然我觉得国家重视视觉有很大的原因是因为它国防上应用多,武器上检测识别跟踪,对军事的作用是巨大的。我们的方法论肯定会变化,我也同意鲍老师观点。如果AI for computing能够发展起来的话,对我们模拟仿真方面会起到很大的作用,比如现在很多在渲染里面加入神经网络。
神经网络始终是有一个问题,就是data-dependent。如果神经网络能当成一个通用计算表达,而不是一个data-dependent表达的话可能用处会更大。但是我也没想通怎么去把它当成一个不data-dependent的表达,因为神经网络的weight一上来是没有意义的。其实我也看到一些neural ode的文章,感觉现在应用的太少了,应付高维空间的表达还是很弱。而且,仿真里面不停地碰撞,不停地加约束,各种约束的变化怎么去做?我觉得他们现在做的AI for science还是偏数据驱动,对原来计算框架没有太多的改变。现在我们可以拿神经网络表达一些材质,但那个也是数据驱动的,相当于是原来的材质模型可能太简单了,用更复杂的函数去表达,但是对计算框架本身大多它没有起到一个很好的作用。
问题:基于NeRF表达的相关生产和处理的工具链包含哪些工具?有哪些形式?面向NeRF专用加速芯片是否会普及。
刘利刚(中国科学技术大学):基于NeRF的3D表达现在大部分还是在重现场景,还没有编辑和创造3D场景的工作。后面需要设计和开发基于NeRF的DCC(数字内容生产)工具,还要考虑基于NeRF表达的动画、物理仿真等方面的应用。
刘烨斌(清华大学):这里面也有个问题,做了这些东西能提供给其它行业什么应用?
刘利刚(中国科学技术大学):我还是想问这个问题,它能不能替换mesh表达?现在是人们无法改变,还是我们没提供足够好的工具给到人们?
张举勇(中国科学技术大学):或者说现在改变的收益太小,如果说你给他提供一个很完整的东西,然后成本又降低50%,我觉得也会用
刘利刚(中国科学技术大学):因为这是一个长期过程,没有让他们看到有好的应用,他们不会换。关键还是技术上你要做到高质量。
鲍虎军(浙江大学):高质量高效率,这两个事情可能比较难。我们就从拍照片这个角度,如果随便拍照就能很快能得到高质量、高效、三维的、又可以运动驱动的模型,这样的一个技术,一个设备,就相当于能替代你现在所有的很厉害的照相机。
周晓巍(浙江大学):我觉得NeRF这个表示在很多应用里它不是刚需。现在我能看到的一个应用是三维视频。因为我们以前媒体主要是图像,然后再到现在视频。以后VR时代肯定是3D的video。三维的视频表示方式是什么?总不能用mesh去表示。我们现在二维的视频里就是一帧帧的2D的图像,三维视频的表示方式到底是什么?
许威威(浙江大学):其实我被NeRF吸引还真是因为全息视频,你拍几张照片就能把所有视点插值出来,全息去观看。
鲍虎军(浙江大学):我先把它移到另一个问题,就是芯片的问题。如果我们用这一套思想去改变传统的图形绘制流水线的话,它的泛化能力能支持各种各样的效果。它实际上是对全局光照绘制方程的一个近似。但它不是真正的唯美的,它不像光线跟踪物理方程求解的那种。如果这个逼近的足够好,而且泛化能力强的话,它哪怕是用传统的AI芯片就能极大地降低功耗,因为它只要有个G-buffer就行了。它用实例化的方法,效率天生的就要比三角形单元来得优越。所以虽然它是一个近似,但是你想传统的图形绘制流水线,用三角形光栅化本身也是一种近似。所以我觉得这一块实际上是需要做一些预处理,这就回到了刚才前面那个问题。实际上图形的计算,为了提高效率,一直以来也是通过预计算,通过数据集,只不过 AI里面是通过现实环境去采集数据,而我们是自己预先用传统的技术去生成数据,这样会真正地提高效率。所以我觉得这个东西会带来很大的变化。
刘利刚(中国科学技术大学):还是要应用驱动,如果有应用肯定会有人往这块挖。但是现在看刚才说的,或许也就三维视频会有应用。
鲍虎军(浙江大学):但如果这样的话,意味着我们modeling的流程要改变。你建好模型以后,我马上要做一个采样,生成它local的参数化光场表达,为了计算一定是前面有个表达。原来我们是变成mesh加上纹理加上BRDF那种就ok了,之后可能就是另一套流程。
刘利刚(中国科学技术大学):另外,只要你后面的计算能够满足用户,前面的东西我宁愿还是用现有的mesh转一下。虽然芯片是适合它的,但未必一定要用它。活血可以先构建mesh表达,再通过计算生成一个光场。
鲍虎军(浙江大学):是这样的,我们现在的模式都是这样,它是兼容传统,就是mesh还是要的,你不能抛掉它。昨天不是在讨论怎么生成NeRF,现在还没办法直接去建一个NeRF。我们现在实际上的方案也是先用传统的方法建好,然后我把它转成NeRF放在一个场景。
刘利刚(中国科学技术大学):但这样还是走了以前烘培的道路。烘培就一个问题,光照不能变,一旦烘培就不容易控制。
鲍虎军(浙江大学):差不多,预计算嘛,很像PRT的,但对PRT大大的进了一步。它可调控的机制更多了,它可泛化。烘培这种就固化掉了。但是我昨天报告的是一种结构化方法,它跟传统的图形是一样的,基本上就是在计算的中间步骤做了一些近似。
许威威(浙江大学):如果说我们做一个全息视频的制作软件,除了拍数据训练生成之外,它应该还有哪些功能,编辑到底应该怎么编辑,是编辑光照还是编辑什么?
鲍虎军(浙江大学):为什么NeRF的加速芯片是需要的,是因为你这个volume rendering。所以我觉得NeRF的专用芯片是比较容易做的,就是加一个z-buffer。因为它有深度有volume,所以把buffer加到AI芯片上就构成了NeRF芯片。但针对这个AI芯片要怎么架构,多个NPU怎么样配置?这些问题还需要讨论。
刘利刚(中国科学技术大学):我的理解是现在GPU多,NPU少,未来是GPU少NPU多是吗?
鲍虎军(浙江大学):对,整个配置比例会不一样。我们那个做法就是把RT core彻底扔掉,然后把shader抛掉了。因为现在用三角形作为单元的流水线,它一定会走到尽头,功耗的问题解决不掉。我觉得RT core那个是不需要的,那个又耗钱,规模又做不大。就GPU的一些基础功能保留,然后加上NPU,以及一个非常大的z-buffer,这个z-buffer的能力要比传统的GPU要高。
许威威(浙江大学):我想说INGP里的feature grid有没有可能用硬件加速?因为你现在只对MLP进行加速,再把feature grid的东西进行硬件加速有可能吗?
高林(中国科学院计算技术研究所):有一些做深度学习芯片的老师已在开展相关的研究工作了。
许威威(浙江大学):对,如果这个基本数据结构加速了,那我觉得加速率马上就上去了。
许威威(浙江大学):我觉得只要把全息视频给支持好,就是一个非常大的事情,我以后传视频就一个网络。
周晓巍(浙江大学):但全息视频不见得就是这种格式。
许威威(浙江大学):那倒也是,但我意思是只要你照片拍好,马上传到手机上就可以全息地看,我觉得这个事情就能影响到大家的生活。未来的时代里,大家就看全息视频了。
周晓巍(浙江大学):嗯,我觉得他们应该都在考虑这件事情,华为啊中兴啊。
刘利刚(中国科学技术大学):但还是有瓶颈,你随便拍,这个是核心问题就是注册标定你搞不定。
许威威(浙江大学):你得有硬件在里面。你不能纯视觉搞,算法没那么稳定的。
问题:当前NeRF在哪些方向最可能出现实际落地应用?在不同方向落地应用的时间预测?各需解决什么问题。
刘烨斌(清华大学): 我觉得可能是那种谷歌百度地图,它要zoom in 去看街景的时候,是不是会被NeRF取代,这个事情可能可以考虑一下。
许威威(浙江大学): 但我觉得NeRF做到那一点还很长,4k8k的分辨率就是一个很大的瓶颈。光训练都已经需要那么高清,要让NeRF生成的那么高清,现在我觉得暂时是没法达到的。
许岚(上海科技大学): 最容易落地的可能反而是在替换逆向过程的重建里面。
许威威(浙江大学): 对,重建上我觉得是可以的,刚才我们要讨论的主要是正向过程上面到底能发挥什么作用。
许岚(上海科技大学): 正向过程,有点像是我要把这种自由视点能力下放给一个普通用户。
许威威(浙江大学): 没错就是这个意思。
许岚(上海科技大学): 但普通用户需要这个东西干什么?我要分享我的生活,它需要一种形式是类似短视频一样可以让别人有分享欲的
许威威(浙江大学): 我觉得如果动态NeRF解决了,我在手机上也许不需要那么高分辨率,我坐那看一看跳舞对吧?但是话又说回来,就是说NeRF现在子弹时间这一应用,其实它很简单,它不需要算法,它多布几个相机直接插值就结束了。
鲍虎军(浙江大学): 我觉得它是一个非常好的写实工具。写实就跟真实的要一模一样,你如果能做的高质量高效率,那么大家就想象我们的传媒系统,应用其实非常多。实际上最直观的,比如说现在所有的体育直播。我一直觉得你如果能把它解决掉,就能进行三维的直播,就变成高度沉浸式的,你可以不到现场去但比现场看得更清晰,以任意的角度任意的方式。所以你如果能做到这些东西,就改变了未来对传播的方式。
我觉得目前的应用可能与你技术的成熟度相关。然后哪怕现在没什么应用,可能也会在别的领域有所贡献,比如现在像NeuS或者其它的从NeRF的思想演化而来的很多技术。所以它本身可能不会有很大应用,但是它的思想在其它地方开花结果。
刘利刚(中国科学技术大学): 还是个成本问题,因为鲍老师说的现在电视台也有,但是成本太高,相机架的密密麻麻的是吗?
鲍虎军(浙江大学): 我一直想做NBA的比赛直播,我老是跟周晓巍说。比如说20个摄像头就在边上同步拍,拍完了以后你把它重建起来。
刘利刚(中国科学技术大学): 有很多企业做的,就是成本太高,他们架一百多个密密麻麻的相机。
张举勇(中国科学技术大学): 我觉得这种做出来要实时才行,否则这个比赛都比完了,你再看有什么意思。
鲍虎军(浙江大学): 当然我跟周晓巍当时讨论的不用NeRF这套技术,我们先把人一个一个建好,然后正面就动捕,直接获取运动去驱动我们的model,这样也是一套方案。但在人激烈对抗的情况下鲁棒性不能保证。有一些情况下肯定可以,比如说拳击运动,那么小的拳台,然后人只有三个。
许威威(浙江大学): 现在NeRF还有很多缺陷,训练很慢,解码速度也不行,所以有很多工作要做。
问题:大家主要关注神经隐式表示在图形学、视觉领域用于几何、三维模型与图像的表达,但它本质上可用于表达任意的数字信号,请问如何看待神经隐式表达在其它相关学科上的前景?
张举勇(中国科学技术大学): 我觉得神经隐式表示本身是一种信号的连续的神经表示,只是我们用来去做图像或者说三维几何。但其实包括像许楠他们也做了对CT,包括昨天过洁讲的声音对吧?其实我觉得在其它的这种学科上,也有很多机会。但我这种交叉的工作做的比较少,想问问各位老师们的建议。
鲍虎军(浙江大学): 我觉得声音克隆有前景。现在TTS这种合成很僵硬,感情不好。神经隐式表示这个是一个非常好的,也许能够学习他的语调。为什么我这么说,我们如果取样本,你都是要生成一个信号跟最后采集的信号对比优化。如果在声音里面,它现在可以合成这个东西,然后跟语调有一个loss的定义,就能反向去优化得到一个声音的情感表达。我觉得声音可能真的可行的,因为它有合成的工具。NeRF这个思路里面,关键就是有一个合成跟GT观测值的比对。
张举勇(中国科学技术大学): 我觉得就把现在NeRF里面volume rendering那里换成声音的某种渲染方式,从神经隐式函数到声音的这部分。
鲍虎军(浙江大学): 还有一个在声音里面,整个声场的模拟问题,我觉得它也是可能解决的,因为声场在三维里面。比如说现在做隐身计算的,就是飞机这种飞行器隐身。关键就是我们这里都要有一个观测值来指导,所以这一类的都需要采集数据。能有观测数据,又能模拟它的话,这一类都是类似的。现在无非几大要素,一个是能有观测值,第二个它能模拟生成,另外一个它整个的优化要在一个连续空间里面。
问题:NeRF表达是否可用于物理仿真、动画等应用?应该如何改进NeRF来适用这些应用?
高林(中国科学院计算技术研究所): 我有个问题,为什么要用NeRF代替传统的物理仿真动画呢?它们有问题吗?
许威威(浙江大学): 其实是这样,比如说你做物理材质的时候,物理材质是个tensor,它是一个非线性的。但现在为了把自由度降下来,都是线性化的假设,我才能够去做到比较高效的仿真。如果用神经网络去表达material,它的函数就能做得很复杂,那么我们就可以做非线性的仿真。
当然我觉得不能叫NeRF,我们这个应该叫neural implicit representation。NeRF太狭窄了,NeRF就只做了radiance field,它一定是做渲染的。我觉得MLP它是一个函数,它不仅仅能用来表达radiance field,它可以表达任意的东西。所以我刚才说的,比如说弹性力曲面的材质,其实是可以用MLP去表达的。最早是像Matthew教授做基于隐式方程的仿真,所以这些东西都可以很自然地跟MLP结合起来。
问题:如何在传统的渲染管线中融合NeRF的渲染方法,如何对NeRF进行准确的几何,材质和光照的估计?
高林(中国科学院计算技术研究所):将来NeRF能不能代替mesh,或者说是NeRF如果是去做渲染的话,怎么跟传统渲染管线去融合。一种的话,我觉得NeRF是很好的一个重建,把NeRF转成传统的表达,然后用传统的表达去渲染。另一种就是这种传统的表达能不能做一个翻译,就是给了一个mesh,原先就是去纹理贴图什么的,能不能把mesh转成一个NeRF的表达,就是这两个之间怎么能做一个相互的转化。另外一个在传统渲染管线的过程中怎么很好地去嵌入NeRF这种渲染,在ray tracing的过程中怎么能把NeRF也比较好地嵌入进去。
鲍虎军(浙江大学): 现在基本上可以了,但我们现在只解决了刚体。你的问题是如果我们已经重建了一个NeRF,要怎么样放到传统的mesh的那套流水线里面去,再进行绘制。还有一个问题是我直接在传统的流水线上增加对一种新的的类似于NeRF的参数化表达,对它绘制里面的一些要素做了特殊化,对它的属性做了NeRF的建模,去提升全局光照计算的效率,最后改变了整套的流水线的形式。所以这里面实际上是这两个问题,我觉得两个都是可能的。我们这个工作历时两年了,我现在初步的一个结论是有可能用这样的一个方式,实际上可能变成一个高度泛化的PRT,这样的一种模式基本上是ok的。
当然你说形变体怎么办?我昨天讲的可比较笼统抽象。实际上一个非常重要的问题是我怎么样把NeRF的表达记录在空间当中,也就是对空间做一个剖分,记录在一些节点上把物体嵌进去。我们现在是以物体为中心,但如果我们变成那样的话,我就对物体的表达无所谓,你嵌到哪个节点上,我就怎样迁移进去。所以我觉得这个技术是存在的。一旦有了这样的办法,相当于它就有了个预计算机器,会极大提高效率。所以高林这个问题实际上很好,它是潜在存在的,但是因为你没去实现过,就很难理解这样怎么可行。实际上是用NeRF的思想去表达了一个各种属性的隐式场,然后怎么样来组装来建立它们之间的关联关系。就是用一种离散的去逼近它,用几个局部的场去组装逼近绘制方程中刻画的光场。
周晓巍(浙江大学): 我感觉就是方程求解的一个预计算。
鲍虎军(浙江大学): 对说得没错,你原来视觉里面NeRF是去拍摄观测值,我现在是预计算生成观测值。
刘利刚(中国科学技术大学): 但你能实时吗?比如说在游戏中它光照变化很快。
鲍虎军(浙江大学): 我现在这个场景全是实时的,一般都是40帧。一个是过网络,一个是全局的可见性计算。所以关键是你怎么样来把一个物理场分解成各种属性场,属性场怎么有效组装去逼近全局的物理场。
问题:隐式表达也是几何造型的基础表达方式之一,在求交等场景下具有独特的优势,如何看待神经隐式表达在几何造型领域的应用?
许威威(浙江大学): 因为我最近看到刘洋工作,刘洋是做Half space,然后它就可以用MLP去表达,一边是0一边是1。
张举勇(中国科学技术大学): 郑老师也有一个,我觉得他们做的很好,用csg然后用神经隐式函数来做交并,上次Asia Graphics的时候我请他们讲了,我就问他神经隐式在CAD领域的前景,但感觉他不是很看好。
许威威(浙江大学): 刘洋是把一个复杂的模型都表示成了一个神经隐式函数,很复杂的,有好几个交在一起的,然后最后可以在各个模型间求交什么的。
鲍虎军(浙江大学): 问题是实际应用在哪些地方要用这样的一种结构。
许威威(浙江大学): 对,但mesh有时候就是不稳定。
刘利刚(中国科学技术大学): 使用隐式函数来做求交等几何计算的研究是很多的。我很好奇的是,是神经网络带来的好处?还是隐式带来好处?
张举勇(中国科学技术大学):以前的隐式表达能力不够强。
许威威(浙江大学):还是因为隐式表达能力够强了,因为现在复杂的曲面它也能表达出来,你用一个函数就可以表达出来了。
刘利刚(中国科学技术大学):因为隐式求交是有好处的,它内外判断非常快,给个值一算一推断就知道是物体内部还是外部。
鲍虎军(浙江大学):昨天韩老师说的实际上非常有道理,怎么样把显式跟隐式有机结合起来。然后用这样的一套表达方式,用隐式来作为全局的一个约束,用显式的方法快速地去迭代逼近,这样可能会解决很多几何计算里面的鲁棒性问题。
许威威(浙江大学):我还有一个疑问,对加工是不是会有影响,因为毕竟是要制造的。就是我其实从视觉上,我已经感觉不出它的区别了,但是一到加工都是10微米以下的精度。
鲍虎军(浙江大学):也不见得,因为很多机械它也没有那么高的精度。关键的是它真正的精度,比如说倒角,我在0.5毫米加工精度下,你的表达能不能达到?它的加工是有一个加工工艺精度极限性,你只要达到它那个就ok。
许威威(浙江大学)所以我觉得这个地方,虽然说你做几何操作是可以的,但是你几何最终的目的是为制造,你能不能满足制造的要求?我觉得以前的隐式表达没有现在用网络的好,因为它只是一个离散的表达,就是我空间剖分这样弄了很多点或者怎么的,我觉得精度肯定是不够的。
张举勇(中国科学技术大学):其实这个问题我有另外一个思考,我觉得现在做几何建模和后面做COM路径规划基本上是独立的。因为我们前面是可微分端到端的,能不能考虑到这种加工的路径规划的误差,反向的去优化前面的modeling这部分,因为它全部都是可微分的。以前是分成几个模块,现在表示可微分了。我最近有个工作是想往这方面做。
刘利刚(中国科学技术大学):以前是分成好多段,现在我们把它串起来了,就好优化了,可能就带来了一些机会。
鲍虎军(浙江大学):因为NeRF的思路,它转到图形领域,包括建模,你一定要用它的思想,用它去重构我们关键的流程。比如说我们在建模阶段,并不是说要把现在视觉那一套拿过来。它核心还是这一套的思路,就用MLP去表达某个曲面或者某个东西。另外一个我用它怎么样来改变我里面的计算流程,我们的数据并不是说要你采集来的,我是通过前面的计算来算出我的观测值,这样去改变我能保证精度。你要搞一套新的几何计算引擎,你为什么一定要传统的那一套?
许威威(浙江大学):对,但是我要提一点,虽然隐式表达求交是有优势的,但加工最后还是要样条曲线曲面,你还要转回来。就是转回来的过程我觉得也挺复杂的。
鲍虎军(浙江大学):不,是你理解错了,它还是在传统的参数表达下,我的隐式是在导引它的计算,提升它的鲁棒性,我是作为一个约束在上面。
许威威(浙江大学):我觉得如果能有个硬件能迅速在各种表达间转换就好了。你想转成这个我就转了,我就可以用。
鲍虎军(浙江大学):为什么这是可行?因为我们在显式的求交里面,比如说我两个model,我用参数化或者用样条或者用mesh去表达,我在算求交的时候,我把它们局部的那些地方先去采样建一个NeRF。类似于这样的一个思想,并不是说我预先都把它们早早建好。
许威威(浙江大学):我看他们现在的几何误差表全是psnr这种。我觉得不好。我觉得要按照我们以前的那套去描述它,否则制造行业对NeRF现在这一套一点感觉都没有。
鲍虎军(浙江大学):所以我刚才想NeRF能不能做一个很重要的事情,比如说我一个物体,我建了一个NeRF的表达,我的优化不需要投影到图像,我直接在volume里面去表面上做比对,我的loss直接建立这三维空间上。我想说的是,你看我现在已经有一个物体,我的三维的模型是有的,我现在用NeRF去逼近它,这个时候我本身就三维的,优化的时候MLP直接去跟我表面比较,就不需要要投影。
刘利刚(中国科学技术大学):参数已经有了,还有一个就是语义。如果设计者需要设置这个圆跟那个圆之间半径的某种关系,这种约束好不好加?
张举勇(中国科学技术大学):我觉得晓光昨天画的SKitch那种,稍微改改是可以表达的,我觉得这种只要可以表达,你的约束都可以放在上面。
许威威(浙江大学):但我觉得肯定还是要转的,其实这种约束很复杂的,几百上千个约束都在一起。
刘利刚(中国科学技术大学):还是显隐式混合吧。
许威威(浙江大学):像他们现在做等几何一样,其实说白了就算要统一,它也有不一样的统一表达。
刘利刚(中国科学技术大学):还有隐式表达好不好做CAE及有限元分析。
鲍虎军(浙江大学):它可以做一个什么?就是我用标准件,标准件都是非常标准的数学表达。我们就去看用NeRF、用MLP能不能逼近那个东西,就能分析精度了。
刘利刚(中国科学技术大学):使用隐式函数来求解积分可以用采样的核函数去逼近它,就不用剖析mesh了。mesh是有限元思想,隐函数它就算这个体里面的一个积分。
问题:最近生成模型在语言驱动的二维图像生成领域大放异彩,NeRF与之结合会走出可控三维生成的道路吗?如何结合?
许岚(上海科技大学):我觉得现在这种文本去驱动生成很艺术的、偏原画设计的图片其实已经很强了。但现在没有一个可控的3d的场景生成模型出来,就一种是偏写实的,一种是偏艺术风格。然后我觉得图形学在过去一年,在外界看来爆火的两个点,一个是NeRF,第二个是stable diffusion。就这种给一句话,我能生成一个艺术家都感觉好厉害,可以超过我的东西。这两个点很突出的,它们之间的结合是很多人想做,但没有太好的思路去做的。我是想抛出这个问题,看有没有进一步结合的这种思路,去解决传统的哪怕是逆向过程中的可控生成问题。
刘利刚(中国科学技术大学)这肯定可以,因为神经网络太强大了,所以前面可以结合好多多模态的输入,其它还有什么问题?
张举勇(中国科学技术大学):我觉得我们的AD-NeRF算是这种,输入文本或者语音,然后就让嘴部做对应相应的内容生成。
问题:在深度学习、神经隐式表示出现之前,几何建模、物理模拟等领域的研究方式是对问题进行建模,表达为一个优化问题,并在求解算法的求解效率与精度方面也有很多研究。神经隐式表示出现之后,相关的研究应该如何开展?
张举勇(中国科学技术大学):现在我们的solver用的都是pytorch自带的solver,我们能不能针对数字几何处理,这种神经隐式表示再去做一些新的求解算法。
刘利刚(中国科学技术大学):对,就像我们的安德森加速方法。
张举勇(中国科学技术大学):我觉得这方面还是没什么研究的,但我觉得是值得去做的。也是从数值上面去加速的提升方向之一。
刘利刚(中国科学技术大学):我问一个更普遍的问题,是不是以前使用mesh的几何处理的工作都值得使用NeRF表达来做以便?纯粹为了做而做是不合适的。还是要发挥基于NeRF表达的优势,根据适合的应用来做。
鲍虎军(浙江大学):我现在想知道我给你几个标准件,比如说球面或者什么,再给你一些采样观测值,你到底能给我重建出多少的精度?
张举勇(中国科学技术大学):曾老师那篇文章就给一个点云,比如说机器零件,他就用那个方法去拟合它。
鲍虎军(浙江大学):我们先可以用标准的模型,比如球面或者标准的这种二次曲面。然后我就能证明这样的MLP表示,这样的采样方式,采样的采样率能达到多少精度,有了这个东西,人家说的很多问题都可以回答。
张举勇(中国科学技术大学):我觉得能不能把现在的这种神经隐式函数做的MLP分解为一些基本的东西。比如用字典组合的去拟合,我可能就找到一个稀疏优化这种。我如果是一个标准件,我就可以拟合得非常完美,这种方式就带入了一些基本几何基元的先验。
鲍虎军(浙江大学):你实际上表达就是几套混合表达一套,我用数学的已经表达好,因为这个场景都可以分解成这种基本单元的,然后我用MLP表示又是一套。
张举勇(中国科学技术大学):我就觉得可以就像室内场景对吧?平面比如说刚才周晓巍讲的曼哈顿约束,这些东西我们在CAD模型里面完全可以用同样的方法论去做。
许威威(浙江大学):我先提一个观点,你是想用以前类似于这种连续优化或者凸优化的方式去优化MLP,是不是这个想法?
张举勇(中国科学技术大学):我是想说以前这种网格的处理,像参数化,deformation,对物理仿真,都是搞一个能量,然后研究能量你怎么建模,然后怎么去求解它。你现在表示变了,有文章就说我数字几何处理这套东西表示变了之后,就是神经隐式函数做。比如说我去做vector field,四面体网格生成,参数化其实肯定也要做相应的修改。比如你的数值solver怎么解。
刘利刚(中国科学技术大学):以前用Vector field做四边形网格化,就是为了CAE计算来服务的。现在如果使用隐式表达的话,可能就不需要做网格化了。这些问题就不是问题了,很多问题可能就不再做了。
鲍虎军(浙江大学):比如说我应力分布的计算,或者是衍射场或者一个飞机的流场,有没有可能直接把这个问题接在MLP上表达出来。
许威威(浙江大学):其实隐式表达仿真很早以前就有了。就是以前可能隐式表达还是以离散采样表达为主的,所以在精度上就造成了损失,干不过mesh。现在到了连续表达是不是有机会干过mesh。
鲍虎军(浙江大学):比如说现在最简单的固体力学弹性形变仿真。你如果没有任何网格剖分,然后表面是MLP,你直接用这个场表达,然后直接去模拟,求解拉格朗日方程。为什么流场在力学模拟里面很难,因为它哪怕变成mesh,它的精度也是极低的。实际上现在的有限元力学模拟有些根本就不对,差距很大很大,这是因为它离散的精度和物理模型与现实本身是有差距的。
许威威(浙江大学):如果你对拉格朗日方程仔细分析,其实是内力那一块是最容易用神经网络表达的。我其实是想尝试的,今年好像也有一篇文章在做这个事,已经有人在开始干这个事了。
张举勇(中国科学技术大学):我觉得离散表示还是对它那个点边线边离散,然后组合对吧?
许威威(浙江大学):你在顶点附近你要么是c0c1c2,总而言之你采样表达你就只能做到这一点。
张举勇(中国科学技术大学):是的,离散采样。但我觉得神经隐式函数它在这个上面就有它的优势。
许威威(浙江大学):对神经网络在这方面确实有优势。所以我们在尝试,但我现在不能确定说它一定能干过有限元。
问题:NeRF等工作以MLP表达定义在三维空间上的特征场,但优化速度比较慢,是目前神经隐式表达的应用瓶颈,应该如何提高神经隐式表达构建的速度?
许威威(浙江大学):我为什么觉得神经网络优化慢,第一个因为它是global的,每一个点位置的变化都会影响到全局,所以随着全局影响它会慢。第二点就是说神经网络的weight它是随机初始化的,初值不够好,导致我们现在这种连续优化的方法很难应用。所以我在想能不能给网络提供一个很好的初值。
许岚(上海科技大学):它完全是你前面的feature maniford捏的速度的问题。像INGP,它有很多数学手段,其实是可以让你MLP本身构造变快的。
许威威(浙江大学):我理解是一样的,我理解INGP为什么很快,是因为它提供了local自由度。就像plenoctree,也可以优化的很快,也比MLP优化快很多。
问题:NeRF隐式表达下一步发展的大机会和大方向会在哪里?
鲍虎军(浙江大学):实际上刚才不就在说了,很多的。逆向的是一方面,在正向上,在图形领域从模拟建模、模拟仿真。它是这样的一种表达方式,不见得叫NeRF,应该是神经网络的隐式表达。
许威威(浙江大学):对NeRF这个名字我觉得是不大好的,把自己限死了。Radiance field,很多问题不一定是radiance field,neural implicit representation可能更好。还有人反对implicit的这个词,因为implicit在数学里是f(x)=0隐含的一个曲面。我那边是把它写成neual volumetric field。
总结
刘利刚(中国科学技术大学):我做个简单的总结。首先,非常感谢大家在疫情管控的情况下来线下参加这个沙龙活动。这个活动我跟举勇策划一年了,终于成行了。从我的个人体验来讲,这两天面对面的效果很好,交流和讨论非常充分,我也有很多收获和新的理解。遗憾还是觉得时间不够,有些问题还没有充分展开交流讨论。研讨中遗留了一些问题,可以在之后进行更多的讨论,形式上也可以线上,也可以线下。未来我们继续开展这种形式的沙龙研讨,下一期的沙龙可以征集和规划起来。
鲍虎军(浙江大学):大家辛苦了,我觉得这个研讨会非常有成效。我们也真的希望回答第一个问题,我们要搞出一些原创性的研究工作。我觉得把神经隐式表示用在正向建模方面还是非常有机会的。我也期待大家可能通过总结以后,能够做出这个领域中一些很好的原创性的工作,能够真的为我们未来的发展打下一个很好基础。












